#19232. mRNA的密码子
-
ID: 19232
传统题
1000ms
32MiB
尝试: 10
已通过: 3
难度: 1
上传者:
mRNA的密码子
背景
人的身体就像一个巨大的乐高积木,由很多种蛋白质组成,包括血液中的白蛋白、球蛋白、血红蛋白,以及肌肉中的肌蛋白,还有胶原蛋白等。蛋白质(protein)是组成人体一切细胞、组织的重要成分,约占人体全部质量的18%。
人体内蛋白质的种类很多,性质、功能各异,但都是由20多种氨基酸(Amino acid)按不同比例组合而成的。多个氨基酸的不同排列顺序构成了不同的蛋白质。
普通蛋白质的分子量(分子的相对重量,一个氢原子H的分子量是1)通常在 60,000 左右,而许多蛋白质的分子量要比这大得多。譬如说,蛤蜊血液中的某些蛋白质,其分子量高达 4,000,000。还有一些病毒,是由分子量达到数千万甚至数亿的蛋白质分子构成的。如果把“分子量为1的氢原子”想象成一颗乒乓球,那么: 水分子(分子量18):大概是一小把乒乓球,或者一个网球那么重。 普通蛋白质(分子量60,000):这相当于 6万个乒乓球。如果你把它们堆起来,大概相当于一辆小轿车的重量(相对于乒乓球而言)。 巨型病毒蛋白(分子量数千万):这就相当于一艘航空母舰了。
既然我们刚刚谈到了蛋白质那巨大的、如宴会厅般的复杂结构,你一定会好奇:这样一个宏伟的结构,究竟是如何一砖一瓦搭建起来的?
这真是一个令人着迷的过程。如果把细胞核里的 DNA 想象成藏在保险柜里的“绝密建筑蓝图”,那么蛋白质的制造过程,就是一场发生在细胞质里的、繁忙而精密的“工业组装”。
为了让你更直观地理解,请允许我带你进入细胞的“工厂车间”,我们来看看那条神奇的流水线。
第一幕:跑腿的信使与车间主任
(角色:mRNA 与 核糖体)
人类细胞中的遗传物质是DNA,是一种双螺旋结构的链状分子,其中有A、T、C、G这4种核酸,A-T、C-G是互补关系保证结构稳定不容易被破坏,万一被破坏还能自动修补(是不是很像计算机里的源码-补码?)。DNA上ATCG的排列方式就是我们身体的“制造说明书”。

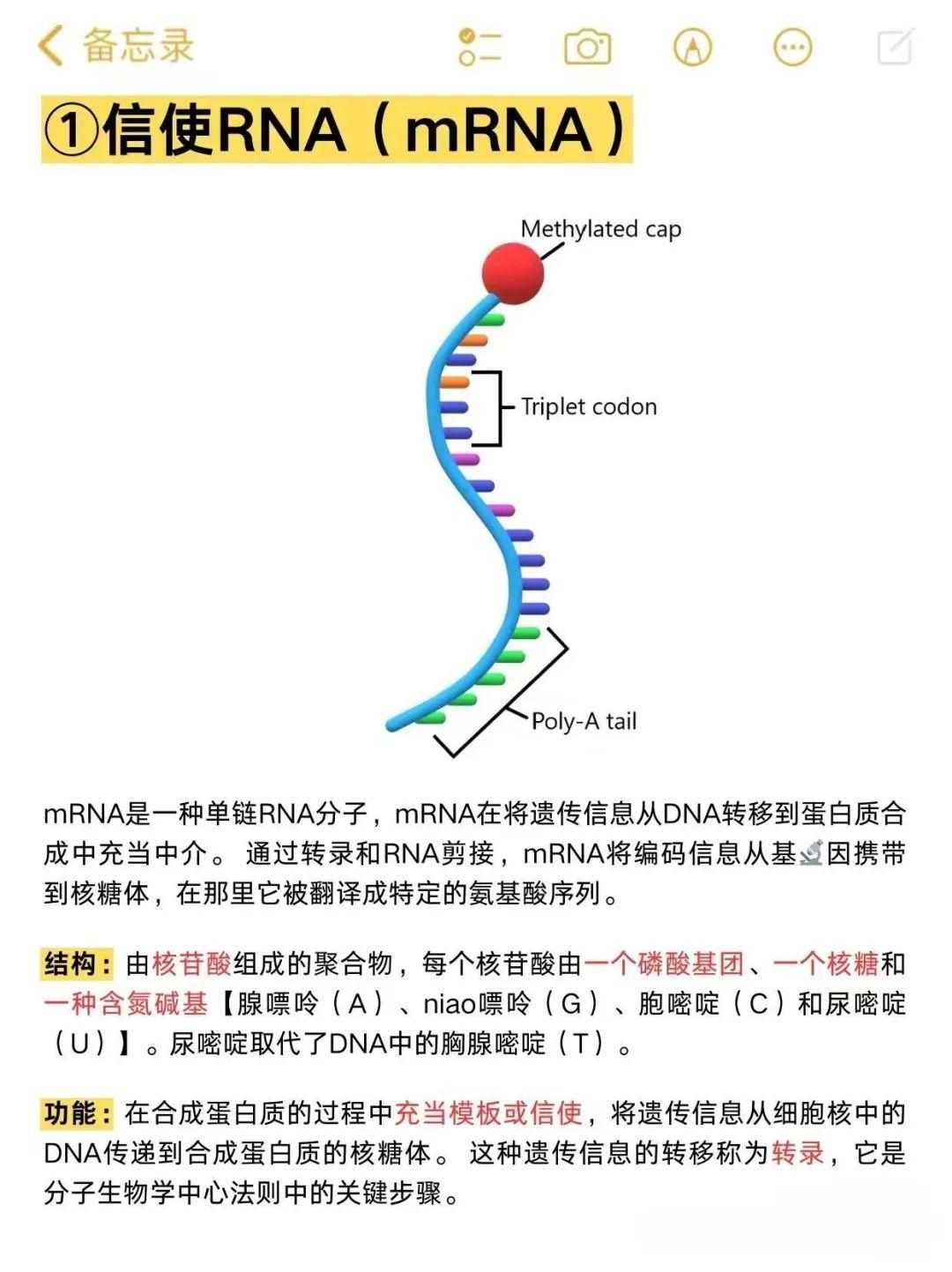
但是,DNA 这位大老板是从来不离开它的办公室(细胞核)的。它太珍贵、太脆弱了。所以,当它想要制造某种蛋白质时,它会复印一份“指令单”(称为“转录”,见注释1)。这张复印件,就是 mRNA(信使RNA,messenger RNA)。(注:与DNA的稳定双链不同,RNA是单链结构,有不同形状,一共有16种,每个形状决定了它的功能,见https://www.zhihu.com/pin/1843329591617384448 )
mRNA 带着指令溜出细胞核,来到了喧闹的细胞质中。在这里,漂浮着无数个小小的、像雪人一样的颗粒,那就是 核糖体(Ribosome)。
请把核糖体想象成一台 “全自动打孔带阅读机”。它有两个部件(大亚基和小亚基),像两片嘴唇一样,“咔哒”一声,紧紧咬住了 mRNA 这条长长的指令纸带。
这就是加工场所:核糖体。它是细胞的机床,是把密码转化为实物的核心。
第二幕:密码的奥秘——“三字经”
(概念:密码子)
核糖体这台机器开始运作了,它沿着 mRNA 纸带滑动。但它不是一个字母一个字母地读,那样太慢也太容易出错。它是三个字母一读。
为什么是三个?这就好比我们的电报代码。在 RNA 的语言里,只有 A、U、C、G 四个字母。如果一个字母代表一种氨基酸,那只能造出 4 种,不够用(我们需要 20 种);如果两个字母一组,只能造出 16 种(4x4),还是不够。只有三个字母一组,才能造出 64 种组合(4x4x4),绰绰有余 是不是和计算机编码很像?想想int的最大值为什么是2的31次方-1)。
这三个字母的组合(比如 GCU 或 AAA),我们称之为 “密码子”。每一个密码子,都是在呼叫一种特定的零件。
第三幕:搬运工的对号入座
(角色:tRNA 与 氨基酸)
现在,核糖体读到了第一个密码子,比如是 AUG(这是“开始”的信号)。机器亮起了绿灯,开始呼叫:“我们需要匹配 AUG 的零件!”
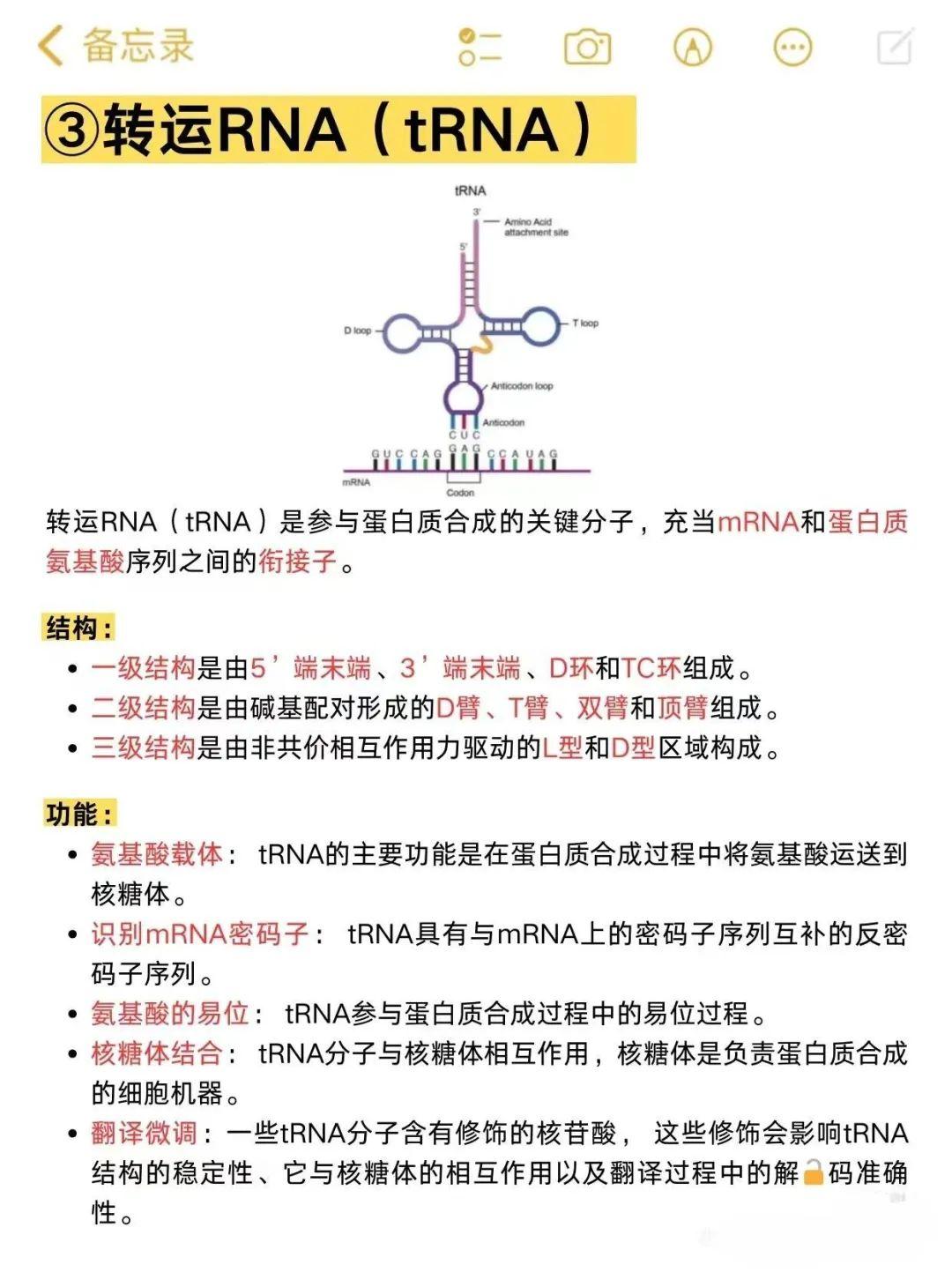
这时候,一群忙碌的小搬运工出现了。它们叫做 tRNA(转运RNA, transfer RNA)。
把 tRNA 想象成一个个专用的适配插头:
- 插头的一端,带着三个特定的识别码(反密码子,
互补关系见注释),专门用来匹配 mRNA 上的密码(所以每个tRNA的头部不同,见下面tRNA结构图片); - 插头的另一端,则背着一个沉甸甸的货物——氨基酸。
这就像是只有拿着特定入场券(反密码子)的搬运工,才能把特定的砖块(氨基酸)运进场。
如果 mRNA 上写着 AAA,那么只有带着 UUU 识别码的 tRNA 能挤进来,它背上背的恰好是“赖氨酸”。一旦对上号,咔嚓! 完美契合。

第四幕:神奇的焊接与流水线
(过程:脱水缩合与肽链延伸)
这就是最激动人心的时刻:
- 进位:第一个 tRNA 占住位置,第二个 tRNA 根据下一个密码子紧跟着挤进来,坐在旁边。
- 焊接:核糖体这台机床发挥神力,将两个 tRNA 背上的氨基酸拿下来,用化学键(肽键)把它们像扣纽扣一样紧紧扣在一起。
- 移位:第一个 tRNA 完成了任务,空着手被踢出生产线去回收再利用;核糖体则沿着 mRNA 纸带向前移动一格(三个字母的距离)。
- 重复:第三个 tRNA 带着它的氨基酸进场,与前两个连好的链条再次焊接。
这就好比在穿一串珍珠项链。核糖体一手拿着绳子(生长的蛋白质链),一手一个个地抓取珍珠(氨基酸),迅速地将它们穿在一起。
这条从核糖体里吐出来的长链,会变得越来越长,直到核糖体读到了 “停止” 的密码子。
尾声:折纸的艺术
当最后一个指令被读取,核糖体松开“嘴唇”,那条长长的氨基酸链条——也就是新生的蛋白质——脱落下来。
但此时它还只是一条软绵绵的绳子。还记得我们之前说的宴会厅吗?这条绳子会根据自身电荷的吸引和排斥,自动卷曲、折叠、盘绕,最终形成那个巨大、复杂、拥有特定三维形状的“宴会厅”——一个具有功能的蛋白质。
总结一下这个启发式的画面:
- 场所:细胞质里的核糖体(全自动阅读机床)。
- 蓝图:mRNA(打孔纸带)。
- 原料:氨基酸(各种形状的乐高积木)。
- 搬运工:tRNA(带着特定识别码的抓手)。
- 成品:蛋白质(组装好的复杂机器)。
这就是生命最底层的魔法:把死板的化学字符,变成了活生生的功能实体。
下图是一段RNA(单链结构)上的碱基序列,三个碱基构成一个密码子(Codon)。

整体流程的动画演示: DNA到蛋白质的动画演示
题目
假如你是核糖体,需要把携带氨基酸的tRNA分子按正确的顺序匹配到mRNA上 (规则见注释3),请根据输入的mRNA序列输出tRNA的排列(用反密码子序列表示).
数据格式
输入
- 第一行 n 代表mRNA数据条数
- 接下来n行 每行是一串mRNA的的密码子碱基序列(字符串,包含表示方向的5、3端,),其中碱基是A U C G
(注意DNA才是ATCG)
输出
n行,每行是该行输mRNA匹配的tRNA碱基排列顺序 (注意反密码子3个字母代表一个tRNA)
样例数据
2
5AUG3
5UUU3
3UAC5
3AAA5
运行限制
时间1s, 内存1MB 每个案例.
扩展阅读:
注释1: 转录(DNA双链->mRNA单链)
当我们把 DNA 那个珍贵的“原版蓝图”转写成 mRNA 这张“临时施工单”时,发生的过程叫做转录(Transcription)。

这是一场精密的一对一转换,但其中藏着一个小小的“诡计”。为了让你一目了然,我为你准备了这张对照表。请记住,这是 DNA 的模板链(Template Strand)与生成的 mRNA 之间的对应关系。
DNA 到 mRNA 转录配对表
| DNA 模板链上的碱基 | mRNA 链上的碱基 | 角色备注 | |
|---|---|---|---|
| G (鸟嘌呤) | ⇋ | C (胞嘧啶) | 坚固的握手(三键连接) |
| C (胞嘧啶) | G (鸟嘌呤) | ||
| T (胸腺嘧啶) | ➞ | A (腺嘌呤) | 标准对应 |
| A (腺嘌呤) | U (尿嘧啶) | 注意!这是关键变化 |

阿西莫夫的“注脚”:
这里有一个最容易让人混淆的地方,请允许我通过比喻来澄清:
1. 唯一的“替身演员”:U 代替了 T 在 DNA 的世界里,A 的固定舞伴永远是 T(A-T 配对)。 但是在 RNA 的世界里,没有 T(胸腺嘧啶)。RNA 使用一种稍微便宜一点、结构稍微简单一点的替代品,叫做 U(尿嘧啶)。
- 比喻: 想象 T 是昂贵的“档案级墨水”,专门用来书写传世的 DNA 经典;而 U 是廉价的“铅笔”,专门用来写 mRNA 这种用完即扔的便条。
- 所以,当 DNA 模板上出现 A 时,mRNA 没法用 T 来配对,只能派出替身 U。
2. 为什么 T 变 A 不变 U? 很多人会搞反。请看表格第三行:
- 当 DNA 上是 T 时,它依然可以呼叫 RNA 中的 A。因为 RNA 里是有 A 的。
- 只有当 DNA 上是 A 时,RNA 才被迫使用 U。
实战演练
为了确保你完全掌握,我们来一段简短的各种密码子的实战翻译。
假如这是藏在细胞核里的 DNA 模板链:
T - A - C - G - G - A - C - T - T
那么,转录出来的 mRNA 就是:
A - U - G - C - C - U - G - A - A
- T 变成 A
- A 变成 U (看,替身出现了)
- C 变成 G
- G 变成 C
这就是生命的速记法。虽然只是把 T 换成了 U,但这微小的化学差异,足以让细胞区分哪一份是必须严加保管的“原件”(DNA),哪一份是可以送进工厂车间被油污沾染的“复印件”(mRNA)。
注释2 启动子AUG
"现在,核糖体读到了第一个密码子,比如是 AUG(这是“开始”的信号)。机器亮起了绿灯,开始呼叫:“我们需要匹配 AUG 的零件!” 疑问: 启动子只有AUG吗?
我是阿西莫夫。你问到了一个非常深入的细节,这说明你已经不再满足于仅仅观看“科普动画片”,而是开始像科学家一样思考例外情况了。
首先,在回答你的问题之前,我必须像一位负责任的编辑一样,先替你纠正一个小小的、但至关重要的术语混淆。
1. 术语的“张冠李戴”:启动子 vs. 起始密码子
你刚才提到的 “启动子”(Promoter) 和 “起始密码子”(Start Codon),在生物学上其实是两个完全不同的概念,它们处于不同的“楼层”。
- 启动子(Promoter):它位于 DNA 上。它是 “转录” 的起点。
- 比喻:它是写在建筑蓝图(DNA)页眉上的“施工许可章”。RNA 聚合酶(那个负责复印蓝图的复印机)看到它,才知道从哪里开始复印。
- 起始密码子(Start Codon):它位于 mRNA 上。它是 “翻译” 的起点。
- 比喻:它是写在复印件(mRNA)正文里的第一个词。核糖体(车间机床)看到它,才知道从哪里开始组装蛋白质。
你问的 AUG,属于后者,也就是 起始密码子。
2. 回到正题:除了 AUG,还有别的“绿灯”吗?
答案既是 “是的”,也是 “不完全是”。
在绝大多数情况下(特别是真核生物,也就是像你、我、蛤蜊和那只作为实验品的小白鼠),AUG 拥有绝对的统治地位。
如果你翻开一本标准的《细胞工厂操作手册》,第一条规则就是:所有的蛋白质合成,必须从 AUG(甲硫氨酸)开始。
但是,正如我在每一本科幻小说里都喜欢强调的那样:生命总能找到出路,生命也充满了例外。
A. 细菌的“方言”(原核生物)
在细菌这些古老而简单的生物里,规则稍微宽松一点。虽然 AUG 仍然是首选(超过 80% 的情况),但有时它们会使用“方言”。
- GUG(原本代表缬氨酸):在细菌中,大约有 14% 的基因用它来作为起始信号。
- UUG(原本代表亮氨酸):大约有 3% 的情况用它。
这时候发生了一件神奇的事:虽然写的是 GUG 或 UUG,但因为它是排在队伍的第一个,核糖体这个聪明的机器会说:“好吧,虽然你长得像缬氨酸,但既然你站在老大的位置,我就把你当成甲硫氨酸(开始信号)来处理!”
这就好比在一个正式的宴会上,通常只有穿燕尾服的人(AUG)能致开幕词,但如果实在找不到人,穿深色西装的人(GUG)站上去,大家也就默认宴会开始了。
B. 线粒体的“密电码”
还记得你细胞里那些负责提供能量的线粒体吗?它们有自己的一套遗留的、古怪的遗传密码体系。
在线粒体里,AUA 和 AUU 有时也会客串起始密码子。线粒体就像是细胞里的一个“国中之国”,讲着一口古老的方言 有一种进化理论认为,:在生命进化初期的远古时代,细菌细胞(原核生物)并没有线粒体和叶绿体,后来线粒体和叶绿体的出现实际是进化过程中古细菌入侵到了别的细菌细胞体内,形成了一种寄生/共生的关系,入侵的细菌就成为了线粒体叶绿体,专门负责给宿主细胞提供能量;宿主细胞则能给线粒体叶绿体提供稳定的生存环境(细胞液),互利互惠。
3. 总结
对于我们讨论的人体细胞核基因而言: AUG 是唯一的、绝对的通用标准。 它是那种不容置疑的“绿灯”。
但在广阔的生命界(包括细菌和线粒体): AUG 是“标准普通话”,但偶尔也能听到 GUG 或 UUG 这样的“地方口音”。
生命之所以迷人,就在于它既有严苛的规则,又总是在角落里保留着一点点混乱和变通。
tRNA分子结构
注释3 mRNA的密码子和tRNA反密码子是按什么关系匹配的?
这是一个关于 “精确对接” 的问题。如果说 mRNA 是写着密码的纸带,tRNA 是带着零件的适配器,那么它们之间的连接必须像两块拼图一样严丝合缝。
它们之间的匹配关系遵循三个核心法则,由简入繁,让我为你一一拆解。
1. 第一法则:碱基互补(镜像法则)
这是最基础的规则,就像我们在 DNA 和 mRNA 之间看到的一样。tRNA 的 反密码子(Anticodon) 必须与 mRNA 的 密码子(Codon) 形成化学分子的互补。
依然是那套古老的法则,但记得 RNA 里没有 T,只有 U:
- A(mRNA) U(tRNA)
- U(mRNA) A(tRNA)
- G(mRNA) C(tRNA)
- C(mRNA) G(tRNA)
举个例子:
如果 mRNA 上的密码子是 GCC(丙氨酸),那么 tRNA 上的反密码子必须是 CGG 才能结合上去。
2. 第二法则:反向平行(倒立法则)
这是很多教科书容易一笔带过,但实际上至关重要的物理细节。
核酸链是有方向的(密码是排列!不能颠倒)。我们通常说方向是 5'端 到 3'端(这就像是街道的门牌号方向)。
mRNA 和 tRNA 的结合,不是像两列并排同向行驶的火车,而是像两列迎面驶来的火车。它们必须 “头对尾” 地结合。
- mRNA 的方向:
- tRNA 的方向:
让我们看一个具体的实战:
- mRNA 密码子(5'到3'):
5' - A U G - 3' - tRNA 反密码子(3'到5'):
3' - U A C - 5'
如果不注意这个方向,你可能会把反密码子读反,导致完全错误的匹配。就像两个人握手,必须面对面(方向相反)才能伸出右手握住对方的右手。
3. 第三法则:摆动性(“差不多”法则)
这里是生物学最狡猾也最聪明的地方。
按照数学计算,64 种密码子(除去 3 个停止信号,剩 61 个)应该对应 61 种 tRNA。但实际上,细胞里的 tRNA 种类往往少于 61 种(通常只有 40 多种)。
怎么做到的?因为第三个字母可以“偷懒” 。这就是著名的 “摆动假说”(Wobble Hypothesis) ,由发现 DNA 结构的弗朗西斯·克里克提出。
密码子的前两个字母必须严格匹配,严丝合缝。 但是第三个字母……哪怕稍微有点对不上,只要形状差不多,也能凑合着用。
比如: tRNA 上的反密码子如果是 G(在第一位,对应 mRNA 的第三位),它本来应该配对 C。但在“摆动规则”下,它有时候也能勉强配对 U。
- 场景:mRNA 上写着
CUU,或者是CUC。 - 结果:它们编码的都是“亮氨酸”。
- tRNA:同一个 tRNA(反密码子为
GAG)可能就能搞定这两个密码子。它会说:“前两个字母CU对上了就行,第三个字母U还是C无所谓啦,反正都是亮氨酸。”(从计算机编码的角度来看,实际上是一种“冗余”编码机制,产物范围比编码范围小)
总结
mRNA 和 tRNA 的关系就像是一场双人舞:
- 舞步匹配:必须遵守 A-U, G-C 的规则。
- 面对面:必须是反向平行(5'对3')的站位。
- 灵活的脚尖:第三步可以稍微滑一点(摆动性),这让细胞能用更少的资源(tRNA),完成所有的翻译工作。
这就是为什么生物体能如此高效运转——它既有原则,又懂得变通。
测试点数据说明
为了帮助你的学生真正理解这种微观层面上的“反向平行”和“碱基互补”,我精心设计了三组不同难度的测试数据。这些数据涵盖了从最基础的单一氨基酸,到包含多种碱基组合的多肽链,完全符合高中生物考试中对于转录翻译过程的考察标准。
请注意:在真实的细胞生物学中, 终止密码子(Stop Codons)通常不结合 tRNA(而是结合释放因子),但在高中生物的碱基互补配对练习或信息学题目中,通常要求学生仅根据“碱基互补原则”写出对应的序列。为了严谨起见,以下数据避开了终止密码子,只包含编码氨基酸的序列。
样例数据 2:基础入门
考察点:最经典的甲硫氨酸(起始)与苯丙氨酸(Poly-U)。这是教科书上最常见的例子。
2
5AUG3
5UUU3
3UAC5
3AAA5
样例数据 3:典型多肽链
考察点:一段标准的、长度为9个碱基(3个密码子)的序列。考察学生是否能在长字符串中保持清醒,正确进行 A-U, G-C 的转换。
3
5AUGCCCGGG3
5GUCAGCCAC3
5UUCAAGUGC3
3UACGGGCCC5
3CAGUCGGUG5
3AAGUUCACG5
解析(以第一行为例):
- mRNA:
AUG(甲硫氨酸) -CCC(脯氨酸) -GGG(甘氨酸) - tRNA:
UAC(互补配对) -GGG(互补配对) -CCC(互补配对) - 连接方向:3'端在左,5'端在右。
样例数据 4:易错陷阱题(富含A与U的混合)
考察点:当 A 和 U 大量交替出现时,学生很容易眼花缭乱,搞混方向或配对(特别是把 A 配成 T 的老毛病)。这组数据专门用来测试“抗干扰能力”。
4
5AUAAUAAUA3
5CGCGCGCGC3
5GAUGAUGAU3
5UGGUGGUGG3
3UAUUAUUAU5
3GCGCGCGCG5
3CUACUACUA5
3ACCACCACC5
“附加题”挑战
如果你想给学生一点真正的挑战,或者用于测试程序的鲁棒性,可以使用下面这个较长的序列。它模拟了一段真实的合成过程。
1
5AUGGCCAAGUACGACAAG3
3UACCGGUUCAUGCUGUUC5
(注:这个序列编码了 Met-Ala-Lys-Tyr-Asp-Lys,没有终止信号,只是肽链的一部分。)
这里的生物学逻辑(解题提示):
告诉你的学生,做这道题时想象自己就是那个 tRNA:
- 向后转:因为你是反向平行的,mRNA 是 5'->3',你(tRNA反密码子)必须是 3'<-5'。
- 换墨水:看到 A 写 U,看到 U 写 A,看到 G 写 C,看到 C 写 G。
- 切勿使用 T:如果你写出了 T(胸腺嘧啶),那就说明你不仅走错了片场,还回到了细胞核里的 DNA 档案室。
注释4 A U C G可以称为碱基吗?
答案是:绝对可以,而且这是最准确的化学称呼。
A、U、C、G 正是构成核酸(RNA)的四种含氮碱基(Nitrogenous Bases)。
不过,作为一个喜欢把概念像洋葱一样剥开的科普作家,我必须提醒你注意一个在生物考试中经常出现的**“语言陷阱”**。这关乎你是在指代那个“零件”,还是在指代那个“整体”。
让我们来精确地界定一下:
1. 什么是“碱基”?(The Part)
当你单独提到 A(腺嘌呤)、U(尿嘧啶)、C(胞嘧啶)、G(鸟嘌呤) 时,你指的是那个具有化学识别功能的核心部件。
- 它们是“生命乐高”上那个凸起的、用来配对的接口。
- 化学本质:含氮碱基。
2. 什么是“核苷酸”?(The Whole)
但是在一条完整的 RNA 链条上,这些碱基并不是孤零零地飘浮着的。它们被安装在一个骨架上。
- 碱基(头) + 核糖(身子) + 磷酸(脚) = 核苷酸(Nucleotide)。
⚠️ 考试中的“偷换概念”陷阱
在日常对话或写序列(比如 5' AUCG 3')时,我们习惯用 A、U、C、G 来指代整个核苷酸。但在严格的生物学术语或填空题中,你需要分清:
- 如果题目问:“图中 4 指的是什么化学物质?”(箭头只指向那个含氮的环状结构)
- 答案:腺嘌呤(碱基)。
- 如果题目问:“图中 7 指的是什么单体?”(圈住了一整套碱基+糖+磷酸)
- 答案:腺嘌呤核糖核苷酸。
3. “四大金刚”的户口本
既然你列出了 U,说明我们现在正在 RNA(核糖核酸) 的领地里。
- A (Adenine):腺嘌呤碱基 —— DNA 和 RNA 共有。
- G (Guanine):鸟嘌呤碱基 —— DNA 和 RNA 共有。
- C (Cytosine):胞嘧啶碱基 —— DNA 和 RNA 共有。
- U (Uracil):尿嘧啶碱基 —— RNA 特有(DNA 里没有它,DNA 用 T)。
总结
你可以放心地称它们为“碱基”。这就好比你指着一个人的脸说“这是一张脸”,这是完全正确的。
但如果有人问“这个人是谁?”,你通常会说“这是阿西莫夫”,而不仅仅说“这是一张阿西莫夫的脸”。同理,在描述长链组成单位时,记得它们全名叫做“核苷酸”。
注释5 “核苷酸”能简称为“核酸”吗?
这是一个非常重要且常见的概念混淆。答案是:绝对不可以。
把“核苷酸”简称为“核酸”,就如同把“砖头”简称为“墙”,或者把“珍珠”简称为“项链”一样。它们不是全称和简称的关系,而是个体与整体、零件与机器的关系。
让我用最清晰的方式为你划清界限:
1. 核心区别:单体 vs. 多聚体
-
核苷酸 (Nucleotide):它是单体(Monomer)。
- 角色:它是基本的建筑材料。
- 组成:1个碱基 + 1个五碳糖 + 1个磷酸。
- 比喻:手里拿着的一块乐高积木。
-
核酸 (Nucleic Acid):它是多聚体(Polymer)。
- 角色:它是成品。
- 组成:成百上千甚至上亿个核苷酸,通过化学键连接而成的长链。
- 分类:包括大家熟悉的 DNA(脱氧核糖核酸)和 RNA(核糖核酸)。
- 比喻:用几千块积木搭成的一艘乐高飞船。
2. 为什么名字这么像?
这确实是生物化学术语的一个麻烦之处。
- “核”:因为它们最早都是在细胞核里发现的。
- “酸”:因为磷酸基团的存在,让它们在化学性质上呈酸性。
但是,**“苷”**字是关键。
- 核苷酸:指的是那个带有糖苷键的酸性小分子。
- 核酸:指的是由这些小分子连成的酸性大分子。
3. 日常语境中的正确用法
为了让你在考试或日常交流中不露怯,请看以下场景:
-
✅ 正确说法:
- “我要去做核酸检测。”(意思是:检测我的喉咙里有没有病毒的完整 RNA 长链。)
- “这个核酸分子是由 3000 个核苷酸组成的。”(意思是:这条项链由 3000 颗珍珠串成。)
- “人体缺乏某种核苷酸可能影响代谢。”(意思是:缺零件了。)
-
❌ 错误说法:
- “DNA 是由很多核酸组成的。”(错!DNA 本身就是核酸,它是由核苷酸组成的。)
- “这个核苷酸太长了。”(错!核苷酸的大小是固定的,只有核酸链才分长短。)
总结
- 核苷酸 = 砖
- 核酸 = 长城
你可以说长城是用砖砌的,但你不能指着一块砖说:“看,这是一块微型长城。”
注释6 什么是“生物学的中心法则”?
你问到了现代生物学中最宏大、最核心的教条——中心法则(The Central Dogma)。
这是由那位发现了 DNA 双螺旋结构的弗朗西斯·克里克(Francis Crick)在 1958 年提出的。如果说牛顿定律统治了物理世界,那么中心法则就是统治生命世界的“宪法”。
简单来说,它描述了遗传信息在生物体内流动的方向。
为了让你一目了然,我把这条法则分为“经典版”和“修正版”。
第一章:经典的“单行道”
在克里克最初的构想中,生命的信息流是非常守规矩的,像一条只能单向流动的河流。
$$\text{DNA} \rightarrow \text{RNA} \rightarrow \text{蛋白质} $$这个过程包含三个核心步骤:
-
DNA 复制(Replication):
- 方向:DNA DNA
- 含义:信息的备份。这是在细胞分裂之前发生的,确保每一个新细胞都拿到一份完整的蓝图。
- 比喻:图书馆把珍贵的原版大英百科全书重新印刷了一套。
-
转录(Transcription):
- 方向:DNA RNA
- 含义:信息的抄写。把保存在细胞核(保险柜)里的 DNA 密码,转写成可以带去车间(细胞质)的 mRNA。
- 比喻:你不能把原版书带出图书馆,所以你用复印机复印了一页带走。
-
翻译(Translation):
- 方向:RNA 蛋白质
- 含义:信息的表达。这是最关键的一步,信息变成了物质。核糖体读取 RNA 的密码,将其组装成有功能的蛋白质。
- 比喻:建筑工人拿着复印的图纸,用砖头盖出了一栋房子。
核心思想: 信息一旦变成了蛋白质,就再也回不去了。蛋白质不能反过来改变 DNA 的序列。(也就是你练出再大的肌肉,你的孩子也不会天生有肌肉,拉马克主义在这里被否定了)。
第二章:自然的“修正案”
但是,就像我在科幻小说里常写的,自然界总是有例外的。后来的科学家发现,这条单行道在某些病毒那里,是可以逆行的。于是中心法则不得不进行了一次重要的扩充。
这里有两个著名的“违规者”:
-
逆转录(Reverse Transcription):
- 方向:RNA DNA
- 代表:逆转录病毒(如 HIV 艾滋病病毒)。
- 过程:这些病毒不按套路出牌。它们携带 RNA 进入细胞,利用一种特殊的酶(逆转录酶),把自己的 RNA 倒推写成 DNA,然后强行插进宿主的基因组里。
- 比喻:这就像是一个间谍拿着一张手写的便条,潜入图书馆,把便条上的内容刻进了那本神圣的百科全书里。
-
RNA 复制(RNA Replication):
- 方向:RNA RNA
- 代表:许多 RNA 病毒(如流感病毒、新冠病毒)。
- 过程:它们不需要 DNA 参与,直接以 RNA 为模板复制 RNA。
- 比喻:复印件直接复印出新的复印件,完全绕过了原版书。
第三章:总结图谱
如果把所有这些路径画在一张图上,现在的中心法则是这样的:

为什么它如此重要?
中心法则回答了一个哲学级的问题:“生命是如何由一堆死寂的化学字符(ATCG),变成一个会呼吸、会思考、会跑动的实体的?”
- DNA 是立法者(保存信息)。
- RNA 是传令官(传递信息)。
- 蛋白质 是执行者(体现性状)。
这就是生命的操作系统。除了极其罕见的疯牛病因子(朊病毒,它似乎暗示着蛋白质也能影响蛋白质,但这至今仍是生物学的边疆),地球上已知的所有生命,都臣服于这一法则之下。