#LC219. 存在重复元素 II
-
ID: 19361
传统题
1000ms
128MiB
尝试: 1
已通过: 1
难度: 10
上传者:
存在重复元素 II
你好,同学。今天我们要一起攻克的是一道非常实用的基础算法题。在 NOI 竞赛中,这属于“数据结构基础”范畴,主要考察你对散列表(哈希表)以及滑动窗口思想的综合运用。
这道题在 LeetCode 上叫《存在重复元素 II》,但在竞赛语境下,它本质上是一个带距离约束的动态查找问题。
一、 预备知识点
- 散列表(Hash Table):在 C++ 竞赛中,通常使用
std::unordered_map。它能让我们以接近 的时间复杂度查找某个数值是否出现过。 - 滑动窗口(Sliding Window)的思想:理解 意味着我们只需要关注当前下标前 个范围内的元素。
- 数值离散化/哈希思想:当数值范围(如 到 )远大于数组长度()时,直接开数组计数会爆内存,必须使用哈希表。
二、 题目描述 (NOI 竞赛风格)
题目名称:存在重复元素 II (Contains Duplicate II)
【问题描述】
给定一个长度为 的整数数组 和一个整数 。
判断数组中是否存在两个不同的下标 和 ,使得 且满足 。
如果存在,输出 YES;否则,输出 NO。
【输入格式】 第一行包含两个正整数 和 。 第二行包含 个以空格分隔的整数,表示数组 的元素。
【输出格式】
输出一个字符串 YES 或 NO。
【样例 1 输入】
4 3
1 2 3 1
【样例 1 输出】
YES
【样例 2 输入】
6 3
1 2 3 1 2 3
【样例 2 输出】
NO
【数据规模与约定】
三、 启发式引导:草稿纸上的推理过程
请拿出草稿纸,我们画图来寻找最高效的方法:
第一步:暴力思维及其瓶颈
思考: 如果我们枚举每一对 ,判断 且距离 。
- 计算: 总共有 对,哪怕只检查距离 以内的,计算量也是 。
- 瓶颈: 当 时,,这超出了 1 秒运算限制(约 次)。我们需要一种只遍历一遍 的方法。
第二步:寻找“记忆”策略
思考: 当我们走到下标 时,我们最想知道什么?
- 核心: 我们想知道:“之前出现过的 ,最近的一次在哪里?”
- 推演: 假设数值 上一次出现的下标是
last_pos[V]。- 如果
i - last_pos[V] <= k,那么我们就找到了! - 如果不满足,或者之前没出现过,我们就更新
last_pos[V] = i,继续往后走。
- 如果
第三步:选择合适的数据结构
思考: 数组元素值达到 ,我们不能开 int last_pos[1000000000]。
- 方案: 使用
unordered_map<int, int>。其中Key存数值, 存它最近一次出现的下标。
四、 算法逻辑流程图
请根据此流程图在脑中构建代码逻辑:
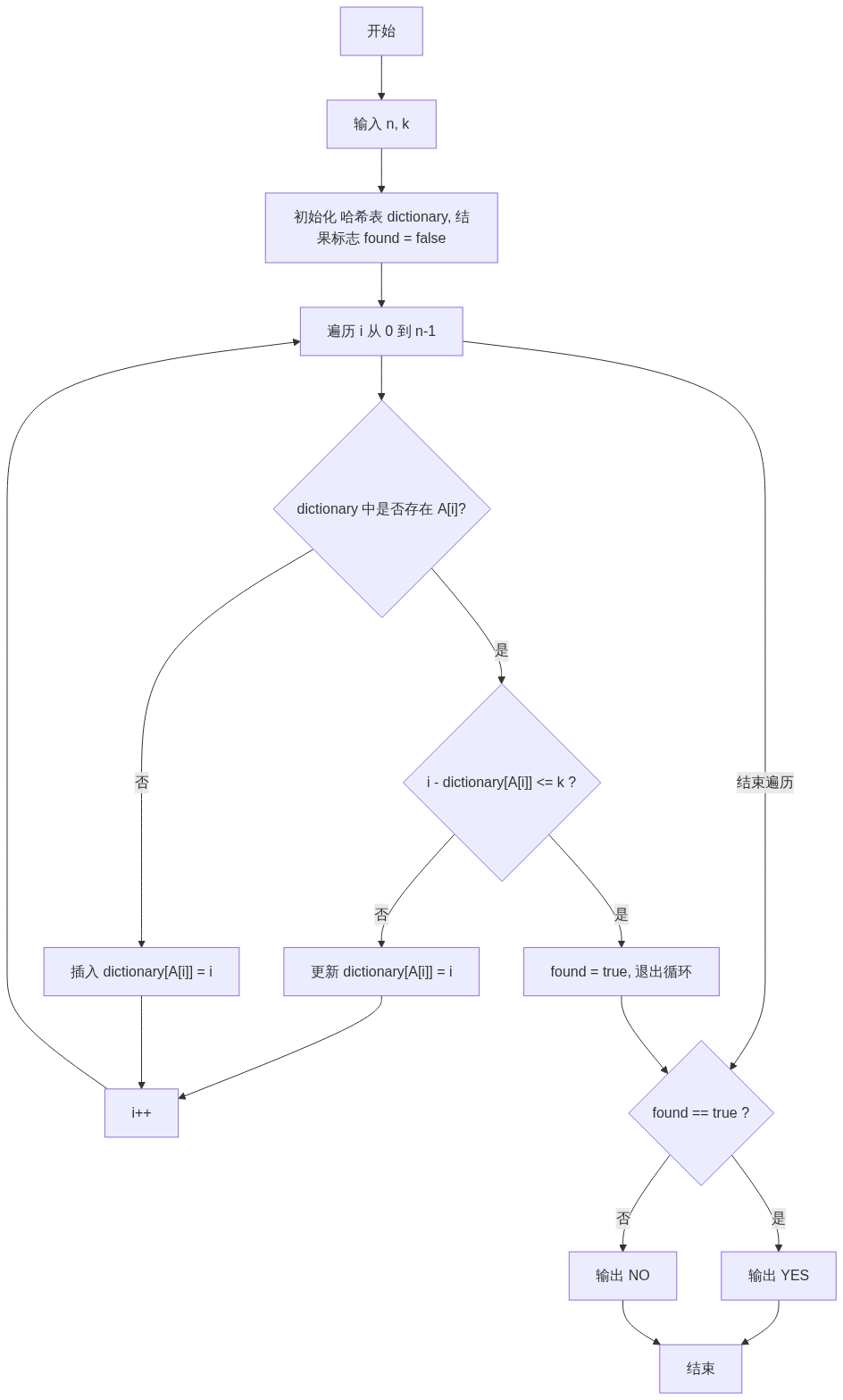
graph TD
A[开始] --> B["输入 n, k"]
B --> C["初始化 哈希表 dictionary, 结果标志 found = false"]
C --> D["遍历 i 从 0 到 n-1"]
D --> E{"dictionary 中是否存在 A[i]?"}
E -- 是 --> F{"i - dictionary[A[i]] <= k ?"}
F -- 是 --> G["found = true, 退出循环"]
F -- 否 --> H["更新 dictionary[A[i]] = i"]
E -- 否 --> I["插入 dictionary[A[i]] = i"]
H --> J["i++"]
I --> J
J --> D
D -- 结束遍历 --> K{"found == true ?"}
G --> K
K -- 是 --> L[输出 YES]
K -- 否 --> M[输出 NO]
L --> N[结束]
M --> N[结束]
五 : 时间与空间复杂度分析
- 时间复杂度分析:
- 我们只对数组进行了一次遍历,复杂度为 。
- 哈希表(
unordered_map)的插入和查找平均复杂度为 。 - 总结:总复杂度为 。在 的数据下,运行速度极快。
- 空间复杂度分析:
- 最坏情况下(数组中没有重复元素),哈希表需要存储 个键值对。
- 总结:空间复杂度为 。对于 的数据,内存占用约数 MB,远低于 NOI 规定的 128MB 或 256MB。
时间复杂度优化建议:
在 NOI 竞赛中,如果发现 unordered_map 的常数较大导致超时(某些测试点会故意构造哈希冲突),可以考虑:
- 预分配空间:
dict.reserve(100005);减少动态扩容。 - 手写哈希或离散化:如果数据极其刁钻,可以使用“排序+去重”的离散化方法,将 变为 ,虽然慢一点但更稳定。
六、 总结:读题时的关键词
在竞赛中识别此类题型的关键词:
- “是否存在两个下标”:暗示查找问题。
- “”:数值匹配,通常需要哈希表或排序。
- “”:局部/距离约束,通常联想到滑动窗口或记录“最后一次出现位置”。
- 数据范围 :排除掉直接开计数数组的可能性,必须用哈希表或离散化。
教练点评: 这道题是理解“空间换时间”的极佳案例。通过哈希表记录位置,我们把一个原本需要嵌套循环的搜索问题,降维成了一次线性扫描。在草稿纸上,你要习惯于记录“状态的更新”,这比单纯的模拟移动更有利于写出无 bug 的代码。加油!