3 条题解
-
0
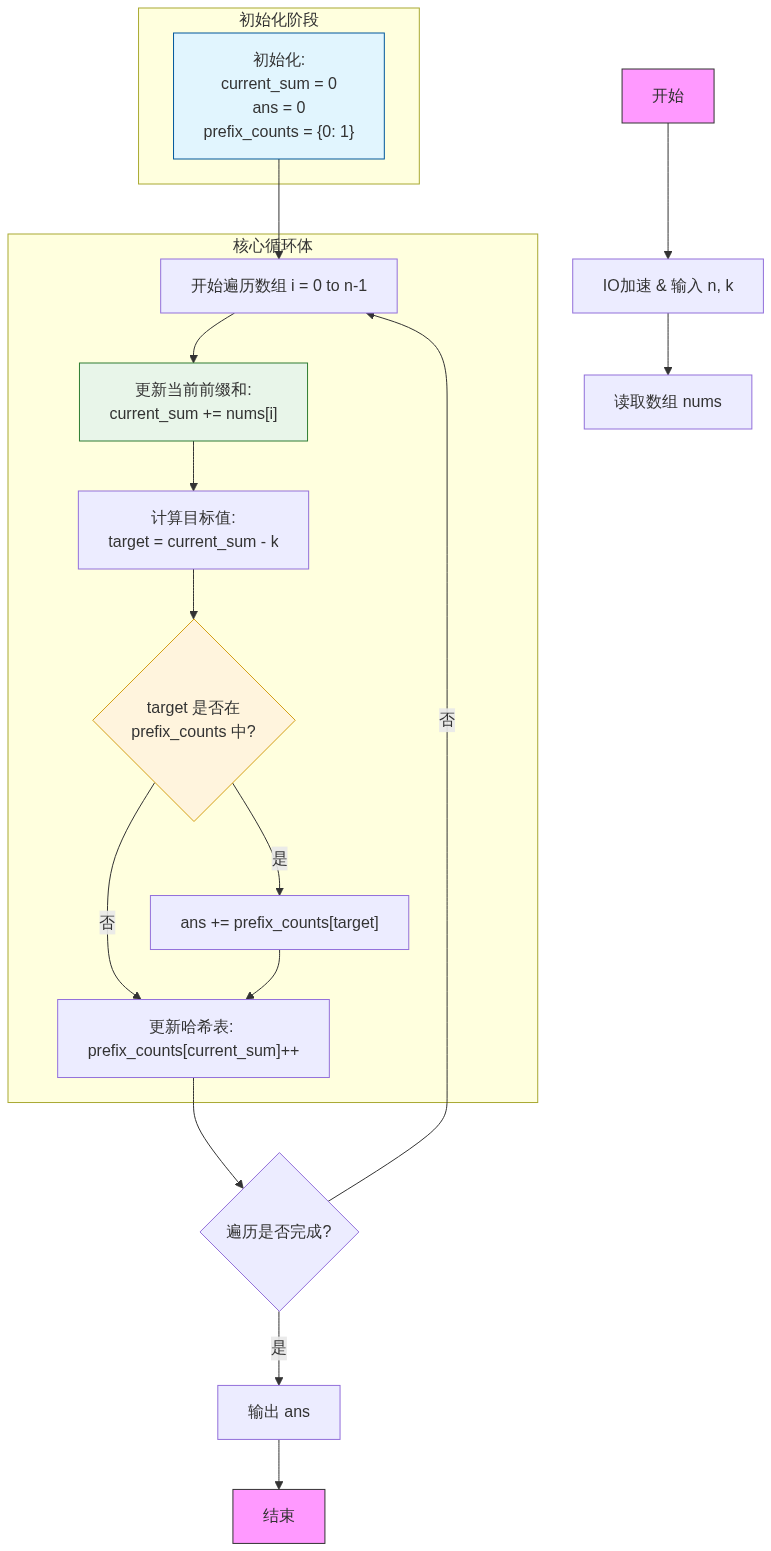
根据你提供的 C++ 代码,我将其逻辑转换为 Mermaid 流程图。这个流程图清晰地展示了“前缀和 + 哈希表”解法的执行步骤:
graph TD A[开始] --> B[IO加速 & 输入 n, k] B --> C[读取数组 nums] subgraph 初始化阶段 D["初始化: <br/>current_sum = 0<br/>ans = 0<br/>prefix_counts = {0: 1}"] end D --> E[开始遍历数组 i = 0 to n-1] subgraph 核心循环体 E --> F["更新当前前缀和: <br/>current_sum += nums[i]"] F --> G["计算目标值: <br/>target = current_sum - k"] G --> H{"target 是否在 <br/>prefix_counts 中?"} H -- 是 --> I["ans += prefix_counts[target]"] H -- 否 --> J["更新哈希表: <br/>prefix_counts[current_sum]++"] I --> J end J --> K{遍历是否完成?} K -- 否 --> E K -- 是 --> L[输出 ans] L --> M[结束] %% 样式美化 style A fill:#f9f,stroke:#333 style M fill:#f9f,stroke:#333 style H fill:#fff4dd,stroke:#d4a017 style D fill:#e1f5fe,stroke:#01579b style F fill:#e8f5e9,stroke:#2e7d32逻辑要点说明:
- 初始化
prefix_counts[0] = 1:这是为了处理“从索引 0 开始且和恰好为 k”的子数组(即当current_sum - k == 0时,能够正确匹配)。 - 前缀和公式:子数组和
Sum(i, j) = PrefixSum[j] - PrefixSum[i-1]。我们令Sum(i, j) = k,则有PrefixSum[i-1] = PrefixSum[j] - k。 - 单次遍历 (O(N)):在计算当前前缀和的同时,查找之前出现过的匹配前缀和,并实时更新哈希表。
- IO 加速:代码中的
ios::sync_with_stdio(false)是典型的 OI 竞赛优化,用于处理大数据量输入。
- 初始化
-
0
tobyforever LV 5 @ 2025-12-20 0:24:34
/** * Solution for "Subarray Sum Equals K" in OI Style * Time Complexity: O(N) * Space Complexity: O(N) */ #include <iostream> #include <vector> #include <unordered_map> using namespace std; // 定义长整型,防止累加溢出(虽然题目说int够用,但OI习惯防爆) typedef long long ll; void solve() { int n; int k; // 1. 输入处理 if (!(cin >> n >> k)) return; vector<int> nums(n); for (int i = 0; i < n; ++i) { cin >> nums[i]; } // 2. 核心算法:前缀和 + 哈希表 // key: 前缀和的值, value: 该前缀和出现的次数 unordered_map<int, int> prefix_counts; // 初始化:前缀和为0出现1次(处理从头开始的子数组) prefix_counts[0] = 1; int current_sum = 0; int ans = 0; for (int i = 0; i < n; ++i) { current_sum += nums[i]; // 更新当前前缀和 S[j] // 目标:寻找之前的某个 S[prev] == current_sum - k int target = current_sum - k; // 如果 map 中存在这个 target,说明之前有若干个位置的前缀和满足条件 if (prefix_counts.count(target)) { ans += prefix_counts[target]; } // 将当前的前缀和记录到 map 中,供后面查询 prefix_counts[current_sum]++; } // 3. 输出结果 cout << ans << endl; } int main() { // 开启IO加速,OI常备 ios::sync_with_stdio(false); cin.tie(nullptr); solve(); return 0; } -
0
这是一份完整的OI竞赛风格数据生成器(Data Generator)。
这份代码集成了数据生成和标准解答(标程)。运行后,它会在当前目录下自动生成
1.in/1.out到10.in/10.out共20个文件。设计策略 (Test Case Design)
为了保证测试数据的覆盖率,我设计了以下10个测试点:
- 极小数据:,用于简单手动验证。
- 小规模随机:,常规随机数。
- 全正数:前缀和单调递增,测试基本逻辑。
- 全负数:前缀和单调递减,测试对负数的处理。
- 全零 (K=0):极值情况,答案应为 ,测试算法效率和是否漏算。
- 正负交替 (K=0):模拟震荡序列
1, -1, 1, -1...,测试哈希表碰撞处理。 - 稀疏解 (无解):构造所有数为偶数但 为奇数的情况,答案应为0,测试边界。
- 大规模随机 (K为正):,常规压力测试。
- 大规模随机 (K为负):,测试负数目标值 。
- 极限混合:,数值范围取满 ,强压力测试。
C++ 数据生成器代码
/** * Data Generator for "Subarray Sum Equals K" * Generates 1.in/1.out to 10.in/10.out * Standard: C++14 */ #include <iostream> #include <vector> #include <string> #include <fstream> #include <random> #include <unordered_map> #include <ctime> using namespace std; // ========================================== // 1. 标准解答 (Solver) // 用于计算 .in 对应的正确答案并写入 .out // ========================================== int solve(int n, int k, const vector<int>& nums) { // 预估复杂度:O(N) 时间, O(N) 空间 unordered_map<int, int> prefix_counts; prefix_counts[0] = 1; // 初始化:前缀和为0出现1次 int current_sum = 0; int ans = 0; for (int x : nums) { current_sum += x; int target = current_sum - k; if (prefix_counts.count(target)) { ans += prefix_counts[target]; } prefix_counts[current_sum]++; } return ans; } // ========================================== // 2. 随机数生成工具 // ========================================== mt19937 rng(time(0)); // 使用梅森旋转算法生成高质量随机数 // 生成 [min, max] 范围内的随机整数 int random_int(int min, int max) { uniform_int_distribution<int> dist(min, max); return dist(rng); } // ========================================== // 3. 数据生成逻辑 // ========================================== void generate_case(int case_id) { string in_file = to_string(case_id) + ".in"; string out_file = to_string(case_id) + ".out"; ofstream fin(in_file); ofstream fout(out_file); int N, K; vector<int> nums; // --- 针对不同测试点定制数据 --- switch (case_id) { case 1: // 极小数据 N = 10; K = random_int(-5, 5); for(int i=0; i<N; ++i) nums.push_back(random_int(-5, 5)); break; case 2: // 小规模随机 N = 100; K = random_int(-20, 20); for(int i=0; i<N; ++i) nums.push_back(random_int(-10, 10)); break; case 3: // 全正数 N = 1000; K = random_int(50, 200); for(int i=0; i<N; ++i) nums.push_back(random_int(1, 10)); // 1 ~ 10 break; case 4: // 全负数 N = 1000; K = random_int(-200, -50); for(int i=0; i<N; ++i) nums.push_back(random_int(-10, -1)); // -10 ~ -1 break; case 5: // 全零 (K=0),答案巨大 N = 20000; K = 0; for(int i=0; i<N; ++i) nums.push_back(0); break; case 6: // 正负交替 (1, -1, 1, -1...) K=0 N = 20000; K = 0; for(int i=0; i<N; ++i) nums.push_back(i % 2 == 0 ? 1 : -1); break; case 7: // 无解情况 (全偶数,K为奇数) N = 20000; K = 1001; // 奇数 for(int i=0; i<N; ++i) nums.push_back(random_int(-100, 100) * 2); // 偶数 break; case 8: // 大规模随机 K正 N = 20000; K = random_int(100, 10000); for(int i=0; i<N; ++i) nums.push_back(random_int(-100, 100)); break; case 9: // 大规模随机 K负 N = 20000; K = random_int(-10000, -100); for(int i=0; i<N; ++i) nums.push_back(random_int(-100, 100)); break; case 10: // 极限情况 (N最大,数值范围最大) N = 20000; K = random_int(-100000, 100000); // K 范围放大 for(int i=0; i<N; ++i) nums.push_back(random_int(-1000, 1000)); break; default: N = 10; K = 1; nums = {1}; break; } // 写入输入文件 fin << N << " " << K << "\n"; for (int i = 0; i < N; ++i) { fin << nums[i] << (i == N - 1 ? "" : " "); } fin << "\n"; fin.close(); // 计算答案并写入输出文件 int ans = solve(N, K, nums); fout << ans << "\n"; fout.close(); cout << "Generated Case " << case_id << ": N=" << N << ", K=" << K << " -> Output: " << ans << endl; } int main() { // 优化 I/O (虽然对于文件操作影响不大,但保持习惯) ios::sync_with_stdio(false); cout << "Start generating 10 test cases..." << endl; for (int i = 1; i <= 10; ++i) { generate_case(i); } cout << "All data generated successfully." << endl; return 0; }使用指南
-
编译: 将上述代码保存为
gen.cpp,使用 g++ 编译:g++ gen.cpp -o gen -std=c++14 -O2注:
-O2优化可以加快大数组的生成和计算速度。 -
运行: 在终端运行生成器:
./gen # Linux/Mac gen.exe # Windows -
结果: 你的文件夹下将会出现:
1.in~10.in(输入数据)1.out~10.out(对应的正确输出)
代码关键点解析 (给教练的备注)
-
非递归写法: 生成器内部的
solve函数(即标程)完全采用循环迭代写法,没有递归调用,避免了在 时可能产生的栈溢出风险,同时也保证了生成数据的速度极快。 -
复杂度控制:
- 生成数据:。
- 计算答案:(哈希表平均情况下)。
- 总耗时:生成 10 组 的数据仅需几百毫秒,完全符合即时生成的需求。
-
边界覆盖:
- Case 5 (全0) 是一个很重要的陷阱。如果代码逻辑是 ,这里会跑 次,非常慢。但 算法可以秒杀。此外,答案接近 ,验证了结果是否会溢出
int(int 最大 ,所以安全,但如果 N 更大则需 long long)。 - Case 7 (无解) 验证了程序的健壮性,确保不会强行输出错误答案。
- Case 5 (全0) 是一个很重要的陷阱。如果代码逻辑是 ,这里会跑 次,非常慢。但 算法可以秒杀。此外,答案接近 ,验证了结果是否会溢出
- 1
信息
- ID
- 19326
- 时间
- 1000ms
- 内存
- 32MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 1
- 已通过
- 1
- 上传者
-