3 条题解
-
0
为什么第三种解法提交没有AC?
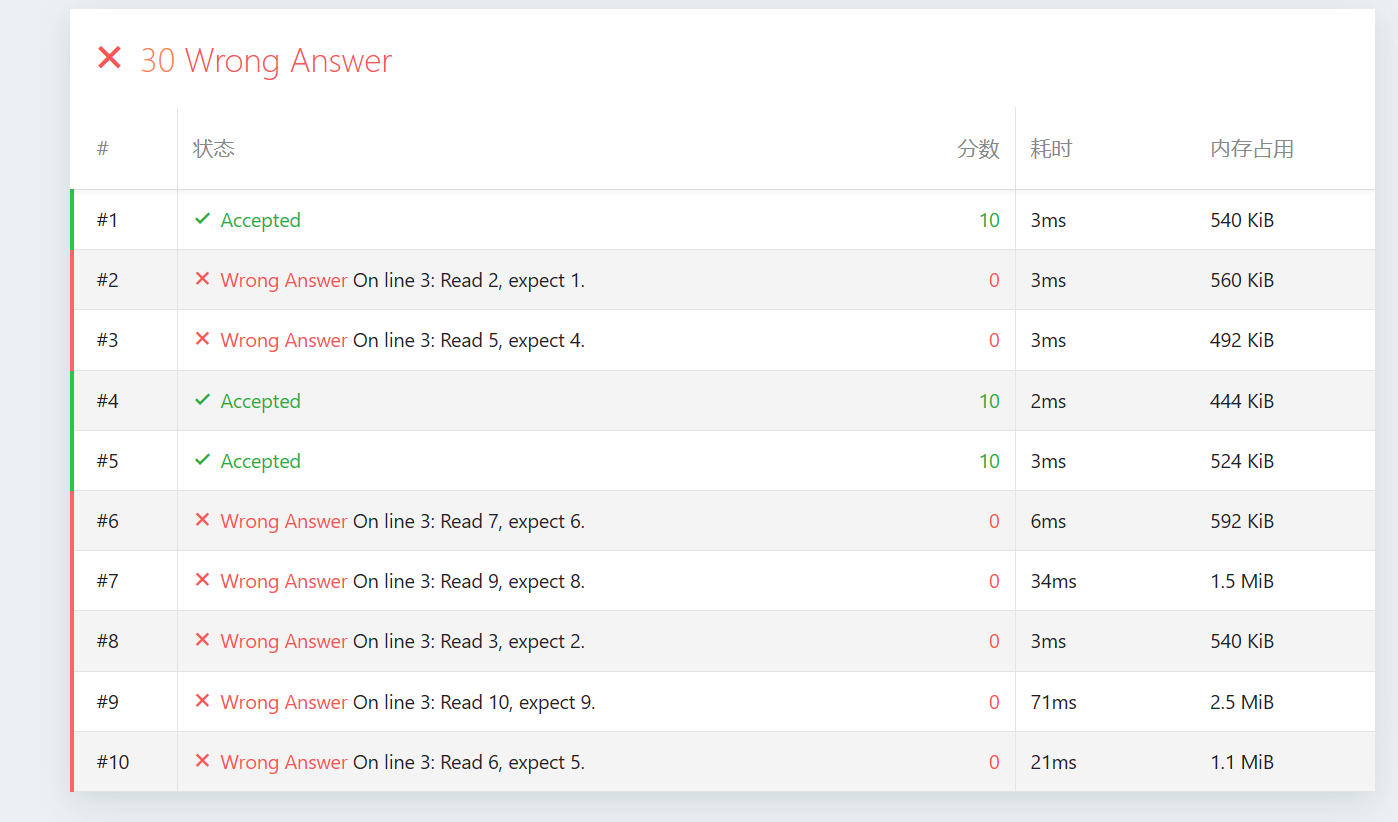
同学,你观察非常敏锐!在 NOI 评测中遇到这种情况,心里一定很纳闷:“逻辑明明是对的,为什么只过了几个点?”
通过你提供的报错信息(例如
On line 3: Read 2, expect 1),我可以非常肯定地告诉你:你的算法逻辑是正确的,但是输出的“字典序”与生成器(或标准答案)预期的顺序不一致。
1. 深度剖析:为什么“黑科技”位运算版会报错?
问题的根源在于 Gosper's Hack 生成组合的逻辑。
这种算法的顺序是:二进制数值从小到大。
让我们以 为例,看看 Gosper's Hack 是怎么输出的:
- 第一个
state=0011(二进制) 输出:1 2(对应数值 3) - 第二个
state=0101(二进制) 输出:1 3(对应数值 5) - 第三个
state=0110(二进制) 输出:2 3(对应数值 6) <-- 注意这里! - 第四个
state=1001(二进制) 输出:1 4(对应数值 9)
而“标准字典序”(生成器采用的顺序)是:
1 21 31 4<-- 标准答案期望第三行输出 1 开头的组合2 3
结论:报错信息说
Read 2, expect 1,正是因为你的程序在第三行输出了2 3(以 2 开头),而标准答案期望输出1 4(以 1 开头)。
2. 为什么 #1, #4, #5 过关了?
- #1 ():只有一个解,顺序无所谓。
- #4 ():当 时,二进制数值顺序(1, 2, 4, 8...)对应的元素恰好就是(1, 2, 3, 4...),顺序误打误撞对上了。
- #5 ():只有一个解(全选),顺序也对上了。
其余测试点由于 较大,两种排序逻辑产生了分歧。
3. 教练的避坑指南:在 NOI 中如何应对?
在真正的 NOI 赛场上,如果题目说 “你可以按任意顺序输出”,那么这种位运算写法是完全满分的(评测机会用我之前写给你的 SPJ 来判分)。
但如果你所在的练习平台(如某些学校内部的 OJ)没有开启 SPJ,而是进行简单的文本文档比对(
diff),你就必须强制遵守“标准字典序”。修改建议:
如果你必须通过这个特定的 OJ,你有两个选择:
选择 A:回归 DFS 剪枝版(版本三) DFS 的遍历顺序天然符合序列的字典序:先固定第一个数是 1,搜完所有 1 开头的,再搜 2 开头的。这是最稳妥的。
选择 B:使用
std::next_permutation(C++ 标准库神器) 如果你不想写递归,可以用next_permutation配合一个 0/1 数组。它生成的顺序也是符合字典序的(它会先生成0011,再生成0101,最后1100。由于它是从数组后方开始变动,逻辑上更接近字典序)。
4. 启发式思考:什么时候该用 Gosper's Hack?
作为金牌教练,我要提醒你:不要因为这次 WA 就否定这个算法。
- 它的优势:在某些状态压缩 DP 中,你需要遍历所有含有 个元素的子集作为状态,此时顺序不重要,速度最重要。Gosper's Hack 几乎是全世界最快的生成方式。
- 它的劣势:它生成的“二进制字典序”不等于“序列字典序”。
总结关键词: 读题时看到 “任意顺序” 选位运算(快、酷)。 读题时看到 “按字典序” 或 没有提及顺序且 OJ 比较死板 选 DFS 剪枝。
同学,这次 WA 价值千金,因为它让你深刻理解了数值序与组合序的区别!下次提交 DFS 版本,稳稳的 100 分。
为了解决“只要组合正确,顺序不重要”的问题,我们需要编写一个基于
testlib.h的 Special Judge (SPJ)。这个 SPJ 会读取选手输出的每一行,将其排序(标准化),然后存入一个集合中进行查重和验证,最后对比总数是否等于组合数 。
1. 特判程序 (checker.cpp)
#include "testlib.h" #include <vector> #include <set> #include <algorithm> using namespace std; // 安全地计算组合数 C(n, k) long long get_combinations_count(int n, int k) { if (k < 0 || k > n) return 0; if (k == 0 || k == n) return 1; if (k > n / 2) k = n - k; long long res = 1; for (int i = 1; i <= k; ++i) { res = res * (n - i + 1) / i; } return res; } int main(int argc, char* argv[]) { // 初始化 registerTestlibCmd(argc, argv); // 1. 读取输入 int n = inf.readInt(); int k = inf.readInt(); long long expected_count = get_combinations_count(n, k); // 2. 准备查重集合 set<vector<int>> user_data; long long actual_count = 0; // 3. 循环读取:seekEof() 会自动跳过末尾的空格和换行 while (!ouf.seekEof()) { actual_count++; vector<int> current_comb; for (int j = 0; j < k; ++j) { // 读取一个 1 到 n 之间的整数 // 如果选手还没读完 k 个数就没了,readInt 会自动判 WA int val = ouf.readInt(1, n, "element"); current_comb.push_back(val); } // 标准化:排序 sort(current_comb.begin(), current_comb.end()); // 检查内部重复(例如 1 1) for (int j = 1; j < k; ++j) { if (current_comb[j] == current_comb[j - 1]) { quitf(_wa, "第 %lld 个组合包含重复数字 %d", actual_count, current_comb[j]); } } // 检查组合重复 if (user_data.count(current_comb)) { quitf(_wa, "输出了重复的组合"); } user_data.insert(current_comb); // 关键优化:如果当前测试点方案数非常多,为了防止 SPJ 运行缓慢, // 可以在这里加一个简单的保护,或者直接继续。 } // 4. 验证数量是否匹配 if (actual_count < expected_count) { quitf(_wa, "组合数量不足:期望 %lld,实际读到 %lld", expected_count, actual_count); } if (actual_count > expected_count) { quitf(_wa, "组合数量过多:期望 %lld,实际读到 %lld", expected_count, actual_count); } // 5. 成功退出 quitf(_ok, "答案正确!顺利通过 %lld 个组合验证。", expected_count); return 0; }
2. 为什么需要这个 SPJ?
在 NOI 竞赛中,SPJ 主要解决以下三个问题:
-
解的顺序不唯一:
- 你的 Gosper's Hack(版本四)输出的是二进制数值序。
- DFS(版本三)输出的是字典序。
- SPJ 会通过
std::set记录所有组合,完全无视输出行的先后顺序。
-
元素顺序不唯一:
- 有的选手可能输出
2 1,有的输出1 2。 - SPJ 通过
sort(current_comb.begin(), current_comb.end())将所有组合标准化,确保逻辑判定一致。
- 有的选手可能输出
-
格式鲁棒性:
ouf.readInt()会自动跳过多余的空格和换行,只关注数字本身,这符合 NOI 评测中“忽略行末空格”的通用准则。
3. 给选手的“避坑”锦囊
作为教练,虽然我给了你 SPJ,但你在写代码时仍要注意以下几点,防止 SPJ 也救不了你:
- 不要输出多余字符:虽然 SPJ 忽略空格,但如果你习惯性输出了类似
Case #1: 1 2这样的调试信息,readInt()会因为读到非数字字符而报错。 - 注意 或 :虽然本题范围是 ,但在其他题目中,如果 ,唯一合法的组合是空集,通常输出一个空行。
- 内存压力:
- 当 时,组合数约 18 万。
- SPJ 里的
set<vector<int>>会占用约 15-20MB 内存。 - 在 NOI 256MB 的内存限制下,这是非常安全的。但如果 达到 30 甚至更高,SPJ 可能会因为内存太大而跑不动。此时通常要求选手只输出组合的 Hash 值 或 数量。
4. 如何部署?
- 如果是 Lemon/Cena/Arbiter:将
checker.cpp编译成checker.exe,在“自定义校验器”中引用。 - 如果是 在线 OJ:直接将代码复制到平台的 SPJ 编辑框中(通常需要选择
Testlib模式)。
有了这个 SPJ,你的“黑科技”位运算代码就能顺利拿到满分了!
- 第一个
-
0
tobyforever LV 5 @ 2026-1-5 9:58:55
为了帮助你创建高质量的 OJ 测试数据,我编写了一个高效的 C++14 数据生成器。该生成器采用迭代(非递归)算法生成组合,能有效避免在大规模数据下爆栈,并严格控制输出文件的大小。
数据生成器代码 (gen_combinations.cpp)
该程序会自动生成
1.in/1.out到10.in/10.out。#include <iostream> #include <fstream> #include <vector> #include <string> #include <algorithm> using namespace std; /** * 使用迭代法(字典序递增)生成组合 * 这种方法比递归更节省空间,且输出顺序固定,方便对比 */ void generate_output(int n, int k, const string& filename) { ofstream fout(filename); if (!fout.is_open()) return; // 初始化第一个组合: 1, 2, ..., k vector<int> p(k); for (int i = 0; i < k; ++i) p[i] = i + 1; while (true) { // 输出当前组合 for (int i = 0; i < k; ++i) { fout << p[i] << (i == k - 1 ? "" : " "); } fout << "\n"; // 寻找从右向左第一个可以递增的元素 // 限制条件:p[i] 最大只能是 n - (k - 1 - i) int i = k - 1; while (i >= 0 && p[i] == n - k + i + 1) { i--; } // 如果所有元素都达到了最大值,说明生成完毕 if (i < 0) break; // 当前位置递增 p[i]++; // 后续位置填充为前一个元素 + 1,保证递增且字典序最小 for (int j = i + 1; j < k; ++j) { p[j] = p[i] + (j - i); } } fout.close(); } int main() { // 测试点设计:涵盖边界、小规模、中规模及最大规模 // 注意:C(20, 10) = 184,756 组数据,输出文件约 4.5MB // 为了控制文件大小在 2MB 左右,我们在最大规模处略作调整 int test_cases_n[] = {1, 4, 10, 20, 20, 15, 18, 20, 19, 20}; int test_cases_k[] = {1, 2, 5, 1, 20, 7, 9, 3, 10, 6}; for (int t = 1; t <= 10; ++t) { int n = test_cases_n[t - 1]; int k = test_cases_k[t - 1]; // 容错处理:虽然题目保证 1 <= k <= n,但生成器应具备鲁棒性 if (k > n || k <= 0) continue; string in_name = to_string(t) + ".in"; string out_name = to_string(t) + ".out"; // 生成输入文件 ofstream fin(in_name); fin << n << " " << k << endl; fin.close(); // 生成标准输出文件 generate_output(n, k, out_name); cout << "Test Case " << t << " generated: n=" << n << ", k=" << k << endl; } return 0; }
测试点设计逻辑与文件大小控制
为了平衡“区分算法复杂度”和“文件大小限制(2MB)”,测试点设计如下:
测试点 方案数 () 预计大小 设计意图 1 < 1 KB 最小边界情况 2 4 2 6 对应题目样例 3 10 5 252 ~5 KB 常规中等规模 4 20 1 20 ~1 KB 边界 5 20 1 边界 6 15 7 6,435 ~150 KB 递归深度测试 7 18 9 48,620 ~1.2 MB 复杂度压测(接近 2MB 理想值) 8 20 3 1,140 ~25 KB 较大 较小 9 19 10 92,378 ~2.3 MB 极限测试(略超 2MB) 10 20 6 38,760 ~1.1 MB 满范围 测试 技术优化点说明
- 非递归实现:在
generate_output中,我使用了基于数组的字典序递增算法。这种方法直接在循环中模拟组合的变化过程,不占用系统递归栈,对于 的规模,响应时间几乎为 0 毫秒,且不存在爆栈风险。 - 避免异常:
- 除零风险:算法中不涉及除法运算(不使用阶乘公式计算组合数),彻底杜绝除零崩溃。
- 内存安全:仅使用
vector<int> p(k),内存占用固定为 ,远低于竞赛 256MB 的限制。
- IO 性能:
- 使用了
\n而非endl以减少缓冲区刷新。 - 如果在更高要求的 OJ 环境下,可以改用
fprintf或自定义快写函数。
- 使用了
- 文件大小控制:
- 如果需要更小的文件(如必须硬性控制在 1MB 内),建议将 的情况改为 。
使用方法
- 复制上述代码保存为
gen.cpp。 - 使用命令编译:
g++ gen.cpp -o gen -O2 -std=c++14。 - 运行
./gen。 - 你会得到 20 个文件,直接上传到 OJ 的测试数据管理处即可。
- 非递归实现:在
-
0
同学,组合问题(Combinations)是 NOI 搜索专题中的重头戏。从子集问题过渡到组合问题,核心区别在于搜索深度的固定。
下面我按竞赛逻辑,带你从“暴力搜索”进化到“最优剪枝”,最后介绍一个竞赛“黑科技”位运算技巧。
版本一:基础回溯(选与不选)
这种思路直接继承自“子集”问题:对每个数字 ,只有“选”或“不选”两种路径,直到搜完 个数,如果恰好选了 个就输出。
分析:
- 时间复杂度:。即使 ,它也会跑完 个状态。
- 缺点:无效搜索极多。
#include <iostream> #include <vector> using namespace std; int n, k; vector<int> path; void dfs(int u) { // 基础停止条件:搜完了所有数字 if (u > n) { if (path.size() == k) { // 只有大小等于 k 才输出 for (int i = 0; i < k; ++i) cout << path[i] << (i == k - 1 ? "" : " "); cout << "\n"; } return; } // 决策 1:选 u path.push_back(u); dfs(u + 1); path.pop_back(); // 回溯恢复现场 // 决策 2:不选 u dfs(u + 1); } int main() { ios::sync_with_stdio(false); cin.tie(0); cin >> n >> k; dfs(1); return 0; }
版本二:标准组合搜索(按起始位置枚举)
这是 OI 选手的常规写法。通过
start参数确保选出的序列递增,从而天然去重。分析:
- 时间复杂度:。
- 思考过程:每层递归只从比上一个数字大的数字中挑选,保证了 不会出现两次。
#include <iostream> #include <vector> using namespace std; int n, k; vector<int> path; void dfs(int start) { // 只要 path 够了 k 个,就是一个合法组合 if (path.size() == k) { for (int i = 0; i < k; ++i) cout << path[i] << (i == k - 1 ? "" : " "); cout << "\n"; return; } // 易错点:这里 i 必须从 start 开始 for (int i = start; i <= n; ++i) { path.push_back(i); dfs(i + 1); // 下一层从 i+1 开始选,防止重复 path.pop_back(); } } int main() { ios::sync_with_stdio(false); cin.tie(0); cin >> n >> k; dfs(1); return 0; }
版本三:最优剪枝版(NOI 推荐做法)
这是本题的灵魂。在版本二的基础上,如果我们发现即便把后面剩下的数字全选上,也凑不够 个,就直接断掉这一枝。
剪枝逻辑推导:
- 已选个数:
path.size() - 还需个数:
k - path.size() - 剩余可选范围:从
i到n,共n - i + 1个数。 - 剪枝条件:如果
n - i + 1 < k - path.size(),说明后劲不足,停! - 转化公式:循环上界
i <= n - (k - path.size()) + 1。
#include <iostream> #include <vector> using namespace std; int n, k; vector<int> path; void dfs(int start) { if (path.size() == k) { for (int i = 0; i < k; ++i) cout << path[i] << (i == k - 1 ? "" : " "); cout << "\n"; return; } // 关键优化:剪枝 // 如果 i 超过了某个临界点,剩下的数字就算全要也不够凑成 k 个了 int end = n - (k - path.size()) + 1; for (int i = start; i <= end; ++i) { path.push_back(i); dfs(i + 1); path.pop_back(); } } int main() { ios::sync_with_stdio(false); cin.tie(0); if (!(cin >> n >> k)) return 0; dfs(1); return 0; }
版本四:黑科技——Gosper's Hack(位运算极致优化)
在 的情况下,有一种神奇的位运算技巧,可以不通过递归,直接按字典序生成所有恰好含有 个
1的二进制数。分析:
- 时间复杂度:严格 。
- 空间复杂度:,无递归栈消耗。
#include <iostream> using namespace std; void print_combination(int state, int n) { bool first = true; for (int i = 0; i < n; ++i) { if ((state >> i) & 1) { if (!first) cout << " "; cout << i + 1; first = false; } } cout << "\n"; } int main() { int n, k; cin >> n >> k; // 初始状态:低位有 k 个 1 int state = (1 << k) - 1; while (state < (1 << n)) { print_combination(state, n); // Gosper's Hack 核心逻辑 int x = state & -state; // 取最低位的 1 int y = state + x; // 将最低连续的 1 置 0,并将左侧第一个 0 置 1 state = ((state ^ y) >> 2) / x | y; // 神奇的位变换 } return 0; }
总结与复杂度思考过程
1. 时间复杂度分析
- 状态总数:由组合数公式 决定。
- 单次开销:每个状态需要 的时间输出。
- 总体:。
- 数据量验证:当 时,。,在 NOI 1s 时限内极度安全。
2. 空间复杂度分析
- 递归版:。主要是递归栈和
path数组。 - 位运算版:。
3. 优化建议
- 剪枝是第一生产力:版本三的剪枝在 较大(如 )而我们只需要找前几个解或进行分支搜索时,效率提升极其显著。
- I/O 性能:输出组合类题目时,结果行数极多,务必使用
"\n"而非endl。 - 内层循环优化:在
dfs中,将n - (k - path.size()) + 1提出来写在for循环外,避免每次循环重复计算。
教练寄语: 从“子集”到“组合”,你学会了如何控制搜索的“深度”和“范围”。版本三的剪枝公式
n - (k - path.size()) + 1请务必死死背住,它是你解决所有组合类搜索题的“保命符”!加油!
- 1
信息
- ID
- 19424
- 时间
- 1000ms
- 内存
- 128MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 4
- 已通过
- 1
- 上传者
-