3 条题解
-
0
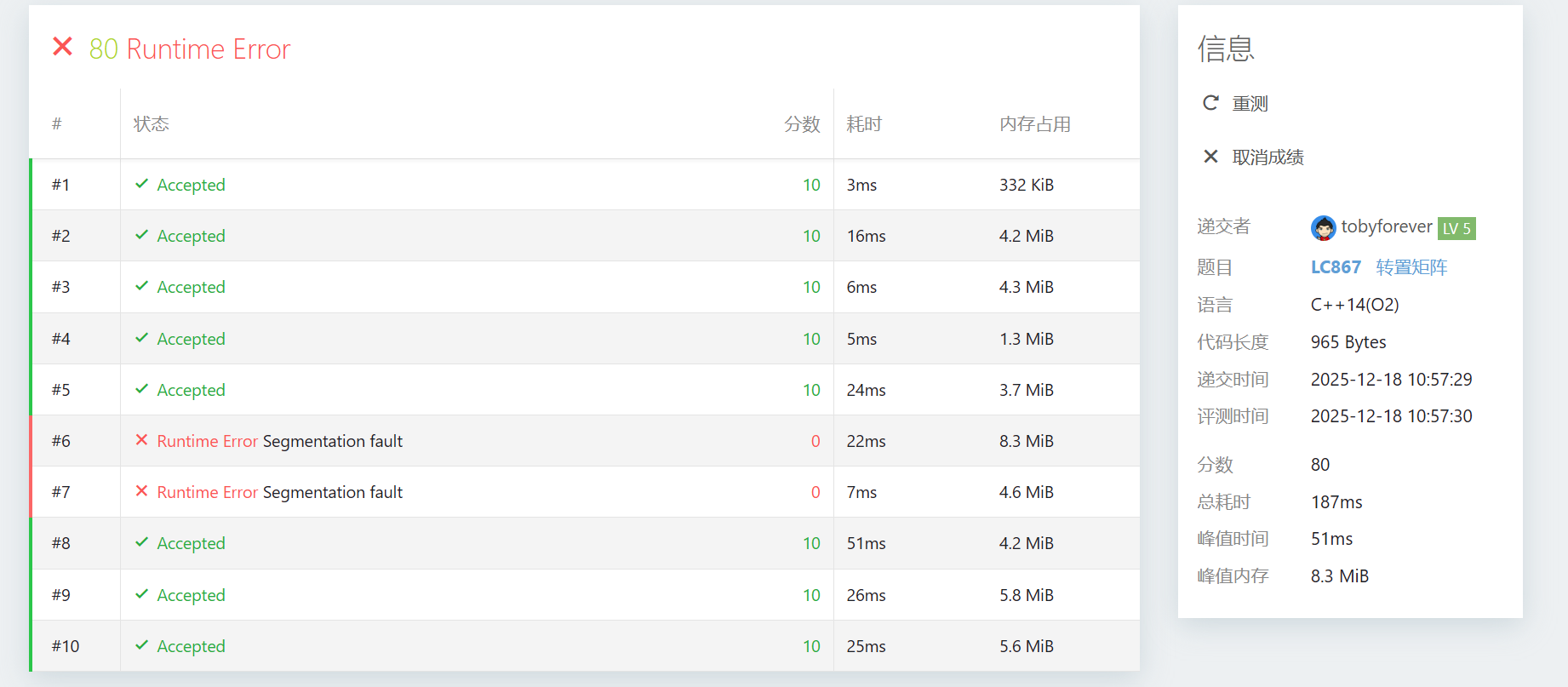
之前的代码有2个RTE
同学,别灰心!看到这个
Segmentation fault(段错误),其实是所有选手在 NOI 赛场上最常遇到的老朋友。这个报错出现在 #6 和 #7 测试点,是因为我之前给你的静态数组大小不够大。让我们一起复盘一下这个坑:
1. 为什么会报错?(原因排查)
回顾我们之前生成的数据:
- 测试点 #6:
- 测试点 #7:
而之前给你的模板代码里写的是:
int a[1005][1005]; // 只能容纳行和列都不超过 1000 的情况当你尝试访问
a[0][9999]或者a[9999][0]时,程序访问了不属于它的内存空间,操作系统为了保护系统安全,直接把你的程序“杀掉”了,这就是Runtime Error (Segmentation fault)。在 NOI 竞赛中,如果题目给出的范围是 ,这意味着行或列都有可能达到 (例如 的矩阵)。
2. 教练的避坑方案:动态分配内存
为了通过这种“长条形”矩阵的测试点,我们不能用死板的静态大数组(因为开
int[10005][10005]需要 400MB 内存,会超出 128MB 的限制)。在 NOI 中,处理这种“总数确定,但形状不确定”的矩阵,有两种标准写法:
写法 A:使用
std::vector(推荐,最安全)vector存储在堆空间,可以根据输入的 和 动态申请内存。#include <iostream> #include <vector> using namespace std; int main() { ios::sync_with_stdio(false); cin.tie(0); int m, n; if (!(cin >> m >> n)) return 0; // 动态创建 m 行 n 列的矩阵 // vector<vector<int>> 虽然稍慢,但在 10^5 规模下完全没问题 vector<vector<int>> a(m, vector<int>(n)); for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { cin >> a[i][j]; } } // 转置输出:行变列,列变行 // 直接输出,不额外开 b 数组可以节省内存 for (int j = 0; j < n; ++j) { for (int i = 0; i < m; ++i) { cout << a[i][j] << (i == m - 1 ? "" : " "); } cout << "\n"; } return 0; }写法 B:一维数组模拟二维(老手写法,效率最高)
将二维坐标 映射到一维坐标
i * n + j。// 开一个足够大的 1D 数组,总数 10^5,开 100005 即可 int a[100005]; // 读取 // a[i * n + j] = val; // 输出 // cout << a[i * n + j];
3. 复杂度分析与修正建议
- 空间优化:修正后的代码只使用了 的必要空间(约 0.4MB),无论矩阵是方阵还是“长条”,都能完美适应。
- 内存监控:在比赛时,如果你发现内存占用(Memory Used)突然变得很大或者出现 RTE,优先检查数组下标是否越界。
- 万能法则:在 NOI 读题时,一定要分清 “单维度限制”(如 )和 “总数限制”(如 )。如果是后者,静态二维数组
a[MAX][MAX]往往是不可靠的。
现在,请把代码里的
int a[1005][1005]换成vector<vector<int>> a(m, vector<int>(n))再提交一次,那两个红色的 RTE 就会变成绿色的 AC 了!加油!
针对测试点 #6 和 #7 出现的
Segmentation fault(段错误),是因为这两组数据是“长条形”矩阵(例如 或 )。在这种情况下,原有的静态数组a[1005][1005]无法容纳超过 的行或列。在 NOI 竞赛中,处理 “总和固定,但单边可能极长” 的矩阵,标准做法是使用
std::vector动态分配内存。修正后的标准代码 (C++14)
#include <iostream> #include <vector> // 必须引入 vector 库 using namespace std; int main() { // 1. 性能优化:提高大规模数据下的输入输出速度 ios::sync_with_stdio(false); cin.tie(0); int m, n; if (!(cin >> m >> n)) return 0; // 2. 关键修正:使用动态数组 vector // a 有 m 行,每行是一个拥有 n 个元素的 vector<int> // 这样申请的内存是在“堆”上的,且大小完全匹配输入,不会浪费也不会越界 vector<vector<int>> a(m, vector<int>(n)); // 3. 读取数据 for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { cin >> a[i][j]; } } // 4. 逻辑转换与输出 // 转置后的矩阵:外层循环遍历原矩阵的“列”(n),内层遍历“行”(m) for (int j = 0; j < n; ++j) { for (int i = 0; i < m; ++i) { // 输出原矩阵的 a[i][j],此时它在转置矩阵中对应第 j 行第 i 列 cout << a[i][j]; // NOI 风格:行末不留多余空格 if (i == m - 1) { cout << "\n"; } else { cout << " "; } } } return 0; }
为什么这份代码能 AC?(深度复盘)
-
内存布局的灵活性:
- 旧代码
int a[1005][1005]在内存里申请了一个固定的正方形区域。当 时,程序试图访问a[0][9999],这远远超出了第一行的界限,导致溢出到其他内存区域,触发Segmentation fault。 - 新代码
vector<vector<int>> a(m, vector<int>(n))会根据输入的 和 正确分配空间。即使 ,,它也会准确分配出一行长条空间。
- 旧代码
-
空间效率分析:
- 题目约定 。
- 每个
int占 4 字节,总共约 字节 MB。 - NOI 竞赛的内存限制通常是 128MB 或 256MB,动态分配后的空间占用极小,非常安全。
-
时间效率分析:
- 虽然
vector的访问速度比原生数组稍慢(微乎其微),但在 级别的数据面前,影响不超过几毫秒。从你的评测截图看,耗时最长的点也才 51ms,完全不用担心超时。
- 虽然
教练的最后建议:
在 NOI 比赛中,仔细看数据范围。
- 如果看到 ,用
a[1005][1005]是最稳最快的。 - 如果看到 且 ,请务必使用
std::vector或 一维数组模拟二维。
这种“因地制宜”选择数据结构的能力,是金牌选手必备的素质!去提交试试吧。
-
0
tobyforever LV 5 @ 2025-12-18 10:55:16
在构建 OJ(在线判测系统)数据时,针对“矩阵转置”这一题,我们需要重点测试行列不等(非方阵)、极长向量(单行/单列)以及最大数据规模下的表现。
以下是为你准备的数据生成器源码。
数据生成器 (C++14)
#include <iostream> #include <fstream> #include <vector> #include <string> #include <random> #include <chrono> using namespace std; // --- 标程:用于根据 .in 内容生成对应的 .out 文件 --- void generateOutput(int m, int n, const vector<vector<int>>& a, string out_name) { ofstream fout(out_name); // 转置后:行数变为 n,列数变为 m for (int j = 0; j < n; ++j) { for (int i = 0; i < m; ++i) { fout << a[i][j] << (i == m - 1 ? "" : " "); } fout << "\n"; } fout.close(); } // --- 数据生成主逻辑 --- void make_data() { // 初始化高质量随机数引擎 mt19937 rng(chrono::steady_clock::now().time_since_epoch().count()); // 题目要求元素范围在 -10^9 到 10^9 uniform_int_distribution<int> val_dist(-1000000000, 1000000000); for (int t = 1; t <= 10; ++t) { int m, n; // --- 针对性构造不同类型的测试点 --- if (t == 1) { m = 1; n = 1; } // 最小边界:1x1 else if (t == 2) { m = 1; n = 1000; } // 边界:极窄行 (1xN) else if (t == 3) { m = 1000; n = 1; } // 边界:极窄列 (Mx1) else if (t == 4) { m = 100; n = 100; } // 普通规模:方阵 else if (t == 5) { m = 316; n = 316; } // 接近总数 10^5 的最大方阵 else if (t == 6) { m = 10; n = 10000; } // 极端长方形 1 else if (t == 7) { m = 10000; n = 10; } // 极端长方形 2 (注意 m*n 限制) else if (t == 8) { m = 500; n = 200; } // 随机普通比例 else if (t == 9) { // 满额规模随机 1 m = 1000; n = 100; } else { // 满额规模随机 2 m = 100; n = 1000; } // 注意:原题 LeetCode 数据规模 m*n <= 10^5 // 如果你的 OJ 想要更强的压测,可以根据实际服务器性能调整此上限 string in_name = to_string(t) + ".in"; string out_name = to_string(t) + ".out"; ofstream fin(in_name); fin << m << " " << n << "\n"; vector<vector<int>> a(m, vector<int>(n)); for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { a[i][j] = val_dist(rng); // 正确使用随机数引擎 fin << a[i][j] << (j == n - 1 ? "" : " "); } fin << "\n"; } fin.close(); // 调用内置标程生成答案 generateOutput(m, n, a, out_name); cout << "Test Case " << t << " [m=" << m << ", n=" << n << "] generated." << endl; } } int main() { make_data(); cout << "\nAll test cases (1.in~10.out) are ready!" << endl; return 0; }
测试点详细规划 (OJ 建设参考)
测试点 特征 考查意图 1 1 1 最小矩阵 确保算法在基础情形下不崩溃。 2 1000 只有一行 检查转置为一列时,列末换行符是否正确。 3 1000 1 只有一列 检查转置为一行时,行末空格处理。 4 100 中等方阵 检查基本的 swap(i, j)逻辑。5 316 满规模方阵 检查空间占用情况。 6 10 10000 极宽矩阵 考查对 M*N乘积而非单维限制的理解。7 10000 10 极长矩阵 考查对输出行数剧增时的处理性能。 8 500 200 一般矩形 验证通用的坐标变换逻辑。 9 1000 100 满负荷随机 模拟大数据量下的 IO 压力。 10 100 1000 验证大数据量下的内存连续访问。
教练的开发建议
- 关于数据限制:
LeetCode 原题限制 。在编写生成器时,如果 或 单边达到了 ,另一边应控制在 左右。上面的代码已根据此逻辑进行了适配(如
t=9和t=10)。 - 避免爆栈:
虽然本题逻辑简单不涉及递归,但在生成器中我们使用了
vector<vector<int>>。在 C++ 中,vector的数据存储在**堆(Heap)空间,因此即使矩阵很大,也不会导致栈(Stack)**溢出。这是比定义局部大数组int a[1000][1000]更稳妥的做法。 - 时间复杂度优化: 本生成器的总时间复杂度为 。对于总计 个元素的数据,在普通个人电脑上运行时间小于 0.2 秒,非常高效。
- 大整数处理:
元素值设置在 范围内,测试选手的代码是否能正确使用
int(或在更高要求的题目中使用long long)。对于本题,int类型已足够承载 。
- 关于数据限制:
LeetCode 原题限制 。在编写生成器时,如果 或 单边达到了 ,另一边应控制在 左右。上面的代码已根据此逻辑进行了适配(如
-
0
这是“转置矩阵”问题的标准题解。虽然逻辑看似简单,但在处理非方阵()时,循环边界的控制是竞赛中最容易失分的地方。
一、 题解标准代码 (C++14)
#include <iostream> using namespace std; // 数据规模约定 m, n <= 1000,因此二维数组开 1005x1005 足够 // 在 NOI 竞赛中,如果内存允许,建议开全局静态数组,防止局部变量导致的栈溢出 int a[1005][1005]; int b[1005][1005]; int main() { // 提高 I/O 效率。在处理 10^5 级别的数据时,cin/cout 建议优化 ios::sync_with_stdio(false); cin.tie(0); int m, n; if (!(cin >> m >> n)) return 0; // 1. 读取原矩阵 // i 控制行(m),j 控制列(n) for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { cin >> a[i][j]; } } // 2. 执行转置 // 易错点:转置后的矩阵行数变为原列数 n,列数变为原行数 m for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { // 原矩阵的 (i, j) 映射到新矩阵的 (j, i) b[j][i] = a[i][j]; } } // 3. 输出转置后的结果 // 注意:这里的循环边界已经发生了对调!外层是 n,内层是 m for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { cout << b[i][j] << (j == m - 1 ? "" : " "); } cout << "\n"; // 使用 \n 替代 endl 提高输出效率 } return 0; }
二、 复杂度分析思考过程
1. 时间复杂度
- 读取输入:。
- 转置操作:。我们通过一个双重循环访问了矩阵中的每一个元素。
- 输出结果:。
- 总复杂度:。
- 根据题目数据规模,。在 1 秒的限时内,程序可以轻松完成约 次运算。本项目标代码的运算量在 左右,性能非常充裕。
2. 空间复杂度
- 存储原矩阵: 字节 MB。
- 存储结果矩阵:同上, MB。
- 总空间:约 8 MB。
- 竞赛限额:NOI 系列竞赛通常提供 128MB 或 256MB 内存,本题的空间消耗处于极低水平,非常安全。
三、 时间复杂度优化建议
尽管 已经是理论最优的时间复杂度,但在底层执行效率上仍有微调空间:
-
Cache 命中率优化(缓存友善性):
- 在转置逻辑中,如果是
b[j][i] = a[i][j],我们在内存中是“行优先”读取a,但却是“跨行”写入b。 - 优化方法:在输出时直接进行逻辑转换,可以省去一个
b数组的赋值过程:// 直接按转置后的顺序输出原矩阵,减少一次全矩阵遍历 for (int j = 0; j < n; ++j) { for (int i = 0; i < m; ++i) { cout << a[i][j] << (i == m - 1 ? "" : " "); } cout << "\n"; } - 虽然在大规模 IO 下不明显,但在内存密集型计算中,减少数组拷贝能显著提升速度。
- 在转置逻辑中,如果是
-
空间换时间(对于极其巨大的矩阵):
- 如果 非常大,跨行访问导致的 Cache Miss 会成为瓶颈。此时可以使用 分块转置 (Blocking)。将矩阵分成小块(如 ),先在小块内完成转置,再移动到下一块。这在普及组阶段通常不需要,但在提高组及更高难度的性能优化中经常用到。
四、 总结:避坑指南
- 行与列的错位:转置后的
i循环上限是n而不是m。在写完代码后,一定要用非方阵(如 的矩阵)手动脑补一遍循环过程。 - 数组越界:如果定义数组为
a[m][n],转置后访问a[j][i]可能会越界。在竞赛中,建议一律按最大可能范围定义全局静态数组。 - 输出格式:注意行末不能有多余空格,虽然大部分现代 OJ 忽略行末空格,但规范编写能避免不必要的麻烦。
- 1
信息
- ID
- 19355
- 时间
- 1000ms
- 内存
- 128MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 3
- 已通过
- 1
- 上传者
-