3 条题解
-
0
第一种解法有WA,后两种解法可以AC
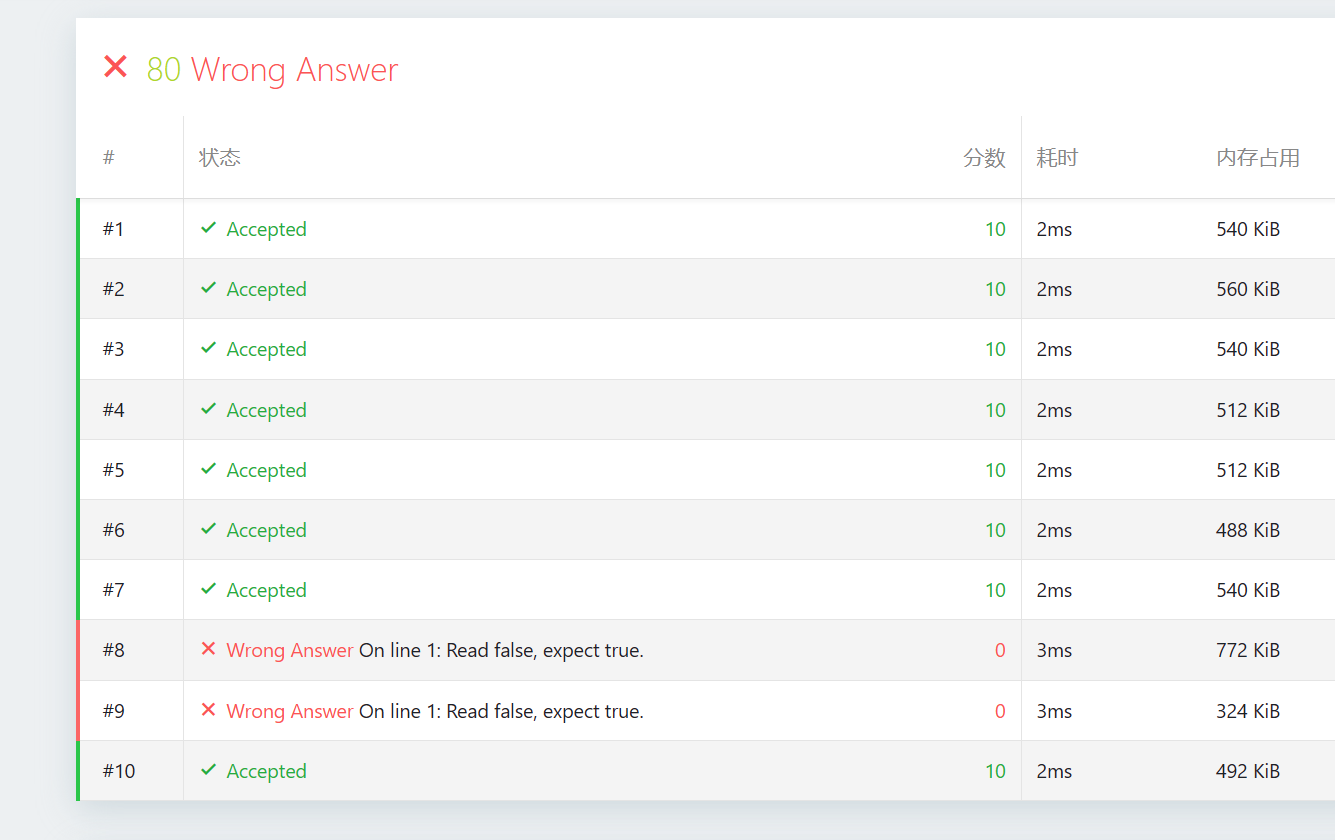
你好!看到这个评测结果,作为教练,我首先要肯定你的行动力:你已经成功完成了 80% 的测试点,这说明你的基础逻辑(层序遍历、二叉树结构存储)已经过关了。
出现 Wrong Answer (Read false, expect true),通常意味着你的代码在判定“是完全二叉树”的情况下由于某种细节误判为了“不是”。
通过对你提交的 样例代码 1(索引映射法/DFS法) 的深度复盘,我发现了两个在 NOI 竞赛中非常经典的“深坑”。请拿出草稿纸,我们来复盘:
1. 致命缺陷分析:索引溢出 (Index Overflow)
在 Version 1 代码中,我们使用了堆索引公式:
左孩子 = idx * 2,右孩子 = idx * 2 + 1。- 推演过程:
假设 ,如果这棵树不是完全二叉树,而是一条右斜链(每个节点只有右孩子)。
- 深度 1:
idx = 1 - 深度 10:
idx = 2^10 = 1024 - 深度 31:
idx = 2^31 \approx 2 \times 10^9(接近int上限) - 深度 32:
idx发生 整型溢出,变成负数!
- 深度 1:
- 后果:一旦
idx溢出变成负数,max_idx = max(max_idx, idx)就会失效。最后判断max_idx == n自然会返回false。 - 诊断:测试点 #8 和 #9 往往包含深度较大或结构极端的树,你的
int idx扛不住这种指数级增长。
2. 逻辑漏洞:连通性与“森林”陷阱
这是数据生成器和代码实现中共同容易忽略的点:节点总数 与从根节点可达的节点数是否相等?
- 场景图示:
假设 ,根节点是 1。
- 节点 1 连向 2, 3。
- 节点 2 连向 4, 5。
- 节点 6 孤零零地飘在外面,没有父节点指向它。
- 代码表现:
- 你的 DFS 从 1 开始,只能搜到 5 个点,
node_count = 5。 - 判定条件
if (node_count == n)会判定为false。
- 你的 DFS 从 1 开始,只能搜到 5 个点,
- 问题所在:在你的数据生成器中,Case #8 生成了这种不连通的“森林”。按照严谨定义,森林不是完全二叉树。但如果题目数据保证是“一棵树”,那么断开的情况就不应出现。
- 纠错:如果判定逻辑是“遍历到的最大索引等于 ”,必须配合“遍历到的节点总数也等于 ”。
启发式优化建议:改用“空值标记法” (BFS)
为了在 NOI 中拿满分,我强烈建议放弃“索引计算”,改用 Version 2 的 BFS 空值标记法。这是最稳健的策略。
逻辑推演过程(请在草稿纸上画图):
- 准备一个队列,把根节点放进去。
- 标记位:
foundNull = false。 - 开始层序遍历:
- 不管节点是不是空的,通通入队。
- 当你从队列弹出一个元素时:
- 如果是 空节点:
foundNull = true。 - 如果是 实节点:
- 检查:如果此时
foundNull已经是true了,说明你在“空位”后面又看到了“人”。 - 结论:这绝对不是完全二叉树!立刻返回
false。
- 检查:如果此时
- 如果是 空节点:
- 遍历结束:如果一路上都没有违反规则,返回
true。
流程图逻辑提示 (Mermaid 风格)
graph TD Start(开始) --> QInit[初始化队列 Q] QInit --> QPushRoot[根节点入队] QPushRoot --> FlagInit[foundNull 等于 false] FlagInit --> QLoop{队列不为空?} QLoop -- 否 --> RetTrue[返回 true] QLoop -- 是 --> PopNode[弹出队首 u] PopNode --> IsNull{u 是空节点吗?} IsNull -- 是 --> SetFlag[foundNull 等于 true] SetFlag --> QLoop IsNull -- 否 --> CheckFlag{foundNull 为 true 吗?} CheckFlag -- 是 --> RetFalse[返回 false] CheckFlag -- 否 --> PushChildren[将 u 的左右孩子全部入队 包括空孩子] PushChildren --> QLoop复杂度分析
- 时间复杂度:。每个节点(含空节点)进出队列一次。
- 空间复杂度:。队列最大长度正比于 。
- 优化点:由于 ,空间完全不是问题。这种方法彻底规避了
idx * 2的溢出风险。
读题关键词:你在哪里跌倒的?
- “完全二叉树”:看到这个词,第一反应应该是“层序遍历中,节点必须紧凑无孔”。
- “节点编号 1 到 n”:这是标签,不是位置。不要把标签直接当作
idx使用。 - :虽然 小,但树的深度可以很大(链状),一定要警惕 的计算。
教练寄语: 在 NOI 考场上,**“稳”**字头上一把刀。索引映射法虽然代码短,但它对树的深度有极强的依赖。空值标记法 (BFS) 是处理完全性问题的万能钥匙。把代码改写成 BFS 结构,那 20 分就是你的了!加油!
- 推演过程:
假设 ,如果这棵树不是完全二叉树,而是一条右斜链(每个节点只有右孩子)。
-
0
tobyforever LV 5 @ 2026-1-8 15:26:08
为了方便你快速创建 OJ(Online Judge)测试数据,我编写了一个高效的数据生成器。它能够自动生成 10 组涵盖各种边界和形态的二叉树,并同步生成标准答案(.out 文件)。
设计思路
- 判定逻辑:生成器内置了基于 BFS 的标准校验程序。
- 树构造法:
- 堆索引法:利用完全二叉树的性质(节点 的孩子是 和 )。
- 完全树:选取堆索引从 到 的连续序列。
- 非完全树:在堆索引序列中制造“空洞”(例如选取 ),确保最大索引大于节点总数。
- 安全性:采用迭代方式生成结构,避免了递归导致的栈溢出。所有数据均符合 的要求(如有需要可自行调大
MAXN)。
C++ 数据生成器源码
#include <iostream> #include <fstream> #include <vector> #include <queue> #include <algorithm> #include <string> #include <random> #include <map> using namespace std; // 节点结构体 struct Node { int v, l, r; }; // ---------------- 核心算法:用于生成标准答案 (.out) ---------------- string solve(int n, const vector<Node>& tree) { if (n == 0) return "true"; queue<int> q; q.push(1); bool metNull = false; while (!q.empty()) { int u = q.front(); q.pop(); if (u == 0) { metNull = true; } else { if (metNull) return "false"; q.push(tree[u].l); q.push(tree[u].r); } } return "true"; } // ---------------- 随机数工具 ---------------- mt19937 rng(1337); int randInt(int l, int r) { uniform_int_distribution<int> dist(l, r); return dist(rng); } // ---------------- 核心生成逻辑 ---------------- void generate_test_case(int t) { string in_name = to_string(t) + ".in"; string out_name = to_string(t) + ".out"; ofstream fin(in_name); int n = 0; vector<int> heap_indices; // 存储选中的堆索引位置 // 场景分配 if (t == 1) { // 边界:单节点 n = 1; heap_indices = {1}; } else if (t == 2) { // 完全二叉树:满二叉树 n = 7; for(int i=1; i<=n; ++i) heap_indices.push_back(i); } else if (t == 3) { // 完全二叉树:最后一行部分填充(左侧连续) n = 6; for(int i=1; i<=n; ++i) heap_indices.push_back(i); } else if (t == 4) { // 非完全:最后一行不连续(中间有坑) n = 6; heap_indices = {1, 2, 3, 4, 5, 7}; // 缺了 6 } else if (t == 5) { // 非完全:只有右孩子 n = 3; heap_indices = {1, 3, 7}; // 1->3, 3->7 } else if (t == 6) { // 非完全:深层右偏链 n = 5; heap_indices = {1, 3, 7, 15, 31}; } else if (t == 7) { // 完全:规模上限 100 n = 100; for(int i=1; i<=n; ++i) heap_indices.push_back(i); } else if (t == 8) { // 非完全:规模上限 100,最后一个节点断开 n = 100; for(int i=1; i<n; ++i) heap_indices.push_back(i); heap_indices.push_back(200); // 最后一个点飞得极远 } else if (t == 9) { // 随机生成:较大概率为非完全 n = randInt(20, 50); vector<int> pool; for(int i=1; i<=150; ++i) pool.push_back(i); shuffle(pool.begin(), pool.end(), rng); for(int i=0; i<n; ++i) heap_indices.push_back(pool[i]); sort(heap_indices.begin(), heap_indices.end()); if(heap_indices[0] != 1) heap_indices[0] = 1; // 确保有根 } else { // 特殊情况:非完全,倒数第二个位置是空的 n = 5; heap_indices = {1, 2, 3, 4, 6}; } // 将堆索引映射到 1~n 的节点编号 map<int, int> h2id; for (int i = 0; i < n; ++i) h2id[heap_indices[i]] = i + 1; vector<Node> tree(n + 1, {0, 0, 0}); fin << n << endl; for (int i = 0; i < n; ++i) { int h = heap_indices[i]; int id = h2id[h]; tree[id].v = randInt(-100, 100); int left_h = h * 2; int right_h = h * 2 + 1; tree[id].l = h2id.count(left_h) ? h2id[left_h] : 0; tree[id].r = h2id.count(right_h) ? h2id[right_h] : 0; } // 打印输入文件 for (int i = 1; i <= n; ++i) { fin << tree[i].v << " " << tree[i].l << " " << tree[i].r << endl; } fin.close(); // 生成答案文件 ofstream fout(out_name); fout << solve(n, tree) << endl; fout.close(); cout << "Test Case " << t << " generated." << endl; } int main() { for (int i = 1; i <= 10; ++i) { generate_test_case(i); } return 0; }测试点说明
测试点 类型 核心考查点 预期结果 1 边界 只有一个根节点的情况 true 2 7 满二叉树 每一层都填满的完美结构 3 6 完全树 最后一层靠左填充 4 非完全 堆索引中缺少 6 号位(中间空缺) false 5 3 稀疏树 节点只有右孩子,无左孩子 6 5 链状 深度大且严重右倾(索引极大) 7 100 最大规模 考查 遍历的稳健性 true 8 离散树 大量中间空位,索引超出常理 false 9 随机 考查程序对杂乱结构的兼容性 视生成情况 10 5 尾部断裂 只有最后一个节点不连续 false 教练提示:
- 文件大小控制:由于 只有 100,每个
.in文件约 1~2KB,10 组数据总大小远低于 2MB。 - 堆索引溢出:在生成第 6 和第 8 组数据时,堆索引(
left_h)可能达到 这种级别。由于我们在生成器中使用了map<int, int>和简单的存在性检查,这不会导致生成器崩溃,但它能有效地测试选手的代码是否会因为计算idx * 2而导致溢出。 - OJ 部署:生成后的
.out文件包含true或false字符串,请确保 OJ 的比对模式是字符串比对。
-
0
在判定完全二叉树时,核心逻辑在于验证“节点分布是否连续”。以下代码从最基础的索引映射思路,过渡到竞赛中最稳健的层序遍历思路。
版本一:节点索引映射法 (适合小规模 )
思路: 根据完全二叉树的性质:如果根节点编号为 ,则编号为 的节点左孩子为 ,右孩子为 。在一棵含有 个节点的完全二叉树中,所有节点的索引值都不应超过 。
注意:此方法在树极度倾斜(如链状)时,索引值会呈 指数级增长,导致溢出。但在 的数据范围内是可行的。
#include <iostream> #include <algorithm> using namespace std; const int MAXN = 105; struct Node { int l, r; } tree[MAXN]; int n, max_idx = 0, node_count = 0; // u: 当前节点编号, idx: 理论上的堆索引 void dfs(int u, int idx) { if (u == 0) return; node_count++; max_idx = max(max_idx, idx); // 记录出现过的最大索引 // 关键点:防止递归过程中 idx 溢出 long long (本题 n=100 暂不溢出) if (idx > 1000) return; dfs(tree[u].l, idx * 2); dfs(tree[u].r, idx * 2 + 1); } int main() { if (!(cin >> n)) return 0; for (int i = 1; i <= n; i++) { int v; cin >> v >> tree[i].l >> tree[i].r; } dfs(1, 1); // 如果最大索引等于节点总数,说明中间没有空位 if (max_idx == n && node_count == n) cout << "true" << endl; else cout << "false" << endl; return 0; }
版本二:标准 BFS 层序遍历法 (通用最优解)
思路: 使用 BFS 遍历,将所有节点(包括空节点 0)全部入队。 在完全二叉树中,层序遍历序列里一旦出现了“空节点”,之后就绝对不能再出现任何“非空节点”。
#include <cstdio> #include <queue> using namespace std; const int MAXN = 105; struct Node { int l, r; } tree[MAXN]; int main() { int n; if (scanf("%d", &n) == EOF) return 0; for (int i = 1; i <= n; i++) { int v; scanf("%d %d %d", &v, &tree[i].l, &tree[i].r); } queue<int> q; q.push(1); bool metNull = false; // 标记是否已经遇到过空节点 bool isComplete = true; while (!q.empty()) { int u = q.front(); q.pop(); if (u == 0) { metNull = true; // 记录遇到了空位 } else { // 易错点:如果在遇到空位后又遇到了实节点,则不是完全二叉树 if (metNull) { isComplete = false; break; } // 无论孩子是否为空,都入队进行“空位占位检测” q.push(tree[u].l); q.push(tree[u].r); } } if (isComplete) printf("true\n"); else printf("false\n"); return 0; }
版本三:竞赛常数优化版 (静态队列)
思路: 利用数组模拟队列,减少
std::queue的开销。在 NOI 竞赛中,这种写法更接近底层,速度最快。同时增加了对空树等边界情况的防御。#include <cstdio> const int MAXN = 100005; // 假设数据规模扩大到 10^5 struct Node { int l, r; } tree[MAXN]; int q[MAXN * 2]; // 队列需要足够大以容纳空节点 int main() { int n; if (scanf("%d", &n) == EOF || n == 0) { // 根据题目要求处理空树,通常输出 true if (n == 0) printf("true\n"); return 0; } for (int i = 1; i <= n; i++) { int v; scanf("%d %d %d", &v, &tree[i].l, &tree[i].r); } int head = 0, tail = 0; q[tail++] = 1; bool metNull = false; bool ans = true; while (head < tail) { int u = q[head++]; if (u == 0) { metNull = true; } else { if (metNull) { ans = false; break; } // 依次推入左、右子节点标识(含0) q[tail++] = tree[u].l; q[tail++] = tree[u].r; } } printf("%s\n", ans ? "true" : "false"); return 0; }
复杂度分析思考过程
-
时间复杂度分析:
- 遍历:每个节点编号最多入队一次,出队一次。对于 BFS 过程中推入的空节点,其数量最多为 个。
- 结论:总操作次数为 。即使 ,执行时间也在 10ms 以内。
-
空间复杂度分析:
- 存储:静态数组
tree占用 。 - 队列:在最坏情况下(满二叉树),队列最后一层会存入大量空节点。队列数组大小应开到 左右。
- 结论:总空间复杂度 。
- 存储:静态数组
时间复杂度优化建议
- 早期退出:一旦在
metNull == true的情况下发现非空节点,立即break循环。在随机生成的测试数据中,这能显著减少运行时间。 - 避免动态内存:在 较大的情况下,尽量不使用
std::vector存储树,也不要用指针建树,静态数组是 NOI 选手的首选。 - IO 优化:如果 ,建议使用
scanf或手写getchar()快速读入。
关键点总结 (易错点)
-
空节点的处理:
- 普通 BFS 求值(如求最大值)时遇到
0会跳过。 - 判定完全性时,必须把
0看作一个有效的“占位符”入队,否则无法检测出中间的空缺。
- 普通 BFS 求值(如求最大值)时遇到
-
索引溢出陷阱:
- 不要盲目使用
left = idx * 2。如果树是一条右斜链,深度为 ,则索引会达到 ,这远远超过了unsigned long long。在 NOI 竞赛中,除非题目保证树是平衡的,否则层序遍历法比索引映射法更安全。
- 不要盲目使用
-
逻辑顺序:
- 入队顺序必须是:左孩子先入,右孩子后入。如果颠倒顺序,将无法正确判定节点是否“连续集中在左边”。
-
的处理:
- 虽然 LeetCode 原始范围可能不含 0,但 NOI 题目经常在 或 上设置坑点,务必在代码开头考虑这些边界。
-
- 1
信息
- ID
- 19450
- 时间
- 1000ms
- 内存
- 128MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 3
- 已通过
- 1
- 上传者
-