4 条题解
-
0
// 包含所有标准库头文件 #include <bits/stdc++.h> // 使用标准命名空间 using namespace std; // 简单哈希表类 class SimpleHashMap { private: // 桶数组:每个桶是一个键值对链表,用于处理哈希冲突 vector<list<pair<int, int>>> buckets; // 当前元素数量 int size; // 哈希表容量 int capacity; // 负载因子阈值:当元素数量超过容量的75%时扩容 const double load_factor = 0.75; // 哈希函数:将键映射到桶索引 int hash(int key) { // 处理负数键,确保返回非负索引 return (key % capacity + capacity) % capacity; } // 扩容函数:当负载因子超过阈值时调用 void resize() { // 保存旧容量 int old_cap = capacity; // 容量翻倍 capacity *= 2; // 创建新的桶数组 vector<list<pair<int, int>>> new_buckets(capacity); // 重新哈希所有元素到新桶 for (int i = 0; i < old_cap; ++i) // 遍历旧桶 for (auto& kv : buckets[i]) { // 遍历桶中的每个键值对 int idx = hash(kv.first); // 计算新的哈希索引 new_buckets[idx].push_back(kv); // 插入到新桶 } // 交换新旧桶数组 buckets.swap(new_buckets); } public: // 构造函数:初始化哈希表 SimpleHashMap() : size(0), capacity(16) { // 调整桶数组大小为初始容量 buckets.resize(capacity); } // put操作:插入或更新键值对 void put(int key, int value) { // 检查是否需要扩容 if (size >= capacity * load_factor) resize(); // 计算键的哈希索引 int idx = hash(key); // 查找键是否已存在 for (auto& kv : buckets[idx]) if (kv.first == key) { // 键存在,更新值 kv.second = value; // 操作完成,返回 return; } // 键不存在,插入新键值对 buckets[idx].emplace_back(key, value); // 元素数量加1 size++; } // get操作:查询键对应的值 int get(int key) { // 计算键的哈希索引 int idx = hash(key); // 查找键 for (auto& kv : buckets[idx]) if (kv.first == key) // 键存在,返回对应的值 return kv.second; // 键不存在,返回-1 return -1; } // remove操作:删除键值对 void remove(int key) { // 计算键的哈希索引 int idx = hash(key); // 查找并删除键 for (auto it = buckets[idx].begin(); it != buckets[idx].end(); ++it) if (it->first == key) { // 找到键,从链表中删除 buckets[idx].erase(it); // 元素数量减1 size--; // 操作完成,返回 return; } } }; // 主函数 int main() { // 输入输出优化,提高速度 ios::sync_with_stdio(false); cin.tie(0); // 操作次数 int N; // 读取操作次数 cin >> N; // 创建哈希表实例 SimpleHashMap map; // 处理N次操作 for (int i = 0; i < N; ++i) { // 操作命令 string op; // 读取操作命令 cin >> op; // 处理put操作 if (op == "put") { // 键和值 int x, y; // 读取键和值 cin >> x >> y; // 调用put方法 map.put(x, y); // 处理get操作 } else if (op == "get") { // 键 int x; // 读取键 cin >> x; // 调用get方法并输出结果 cout << map.get(x) << endl; // 处理remove操作 } else if (op == "remove") { // 键 int x; // 读取键 cin >> x; // 调用remove方法 map.remove(x); } } return 0; } -
0
tobyforever LV 5 @ 2026-1-25 11:50:32
这是一个非常适合初学者理解哈希表底层原理的精简版代码。
特点:
- 结构清晰:使用“数组+链表”的标准拉链法结构。
- 逻辑直观:去掉了复杂的模板和迭代器,使用最基础的指针操作。
- 核心完整:完整包含了哈希计算、冲突处理、节点查找、删除以及核心难点——动态扩容 (Rehash)。
/** * 题目:手写 HashMap 实现原理 (精简教学版) * 语言:C++14 */ #include <iostream> #include <vector> #include <string> using namespace std; // 1. 定义链表节点:用于解决哈希冲突 (拉链法) struct Node { int key; int val; Node* next; // 指向下一个节点 // 构造函数:方便创建新节点 Node(int k, int v, Node* n) : key(k), val(v), next(n) {} }; // 全局变量模拟哈希表 vector<Node*> buckets; // 桶数组 (存放链表头指针) int capacity = 16; // 初始容量 int num_elements = 0; // 当前元素个数 // 2. 扩容函数 (Rehash) - 核心难点 void resize() { int old_cap = capacity; capacity *= 2; // 容量翻倍 // 保存旧桶,创建新桶 vector<Node*> old_buckets = buckets; buckets.assign(capacity, nullptr); // 重置并扩大桶数组,初始化为空 // 遍历旧桶中的所有节点,搬家到新桶 for (int i = 0; i < old_cap; i++) { Node* curr = old_buckets[i]; while (curr != nullptr) { Node* next_node = curr->next; // 先记录下一个节点,防止断链 // 重新计算哈希值 (因为 capacity 变了) int new_idx = curr->key % capacity; // 头插法搬入新家 curr->next = buckets[new_idx]; buckets[new_idx] = curr; curr = next_node; // 继续处理旧链表的下一个 } } } // 3. 插入/更新操作 (Put) void put(int key, int val) { int idx = key % capacity; Node* curr = buckets[idx]; // 遍历链表,看 key 是否已存在 while (curr != nullptr) { if (curr->key == key) { curr->val = val; // 存在则更新值 return; } curr = curr->next; } // 不存在,创建新节点并使用"头插法"插入 buckets[idx] = new Node(key, val, buckets[idx]); num_elements++; // 检查负载因子:如果 元素数量 > 容量 * 0.75,则扩容 if (num_elements * 1.0 / capacity > 0.75) { resize(); } } // 4. 查询操作 (Get) int get(int key) { int idx = key % capacity; Node* curr = buckets[idx]; while (curr != nullptr) { if (curr->key == key) { return curr->val; // 找到返回 value } curr = curr->next; } return -1; // 没找到 } // 5. 删除操作 (Remove) void remove(int key) { int idx = key % capacity; Node* curr = buckets[idx]; Node* prev = nullptr; // 记录前驱节点 while (curr != nullptr) { if (curr->key == key) { // 找到了,准备删除 if (prev == nullptr) { // 删除的是头节点 buckets[idx] = curr->next; } else { // 删除的是中间节点 prev->next = curr->next; } delete curr; // 释放内存 num_elements--; return; } prev = curr; curr = curr->next; } } int main() { // 优化 I/O 速度 ios::sync_with_stdio(false); cin.tie(nullptr); // 初始化桶数组 buckets.assign(capacity, nullptr); int N; cin >> N; while (N--) { string op; cin >> op; int x, y; if (op == "put") { cin >> x >> y; put(x, y); } else if (op == "get") { cin >> x; cout << get(x) << "\n"; } else if (op == "remove") { cin >> x; remove(x); } } return 0; }👨💻 初学者学习重点 (代码解析)
-
数据结构 (
vector<Node*> buckets):- 想象一个大柜子(Vector),里面有很多抽屉。
- 每个抽屉里不直接放东西,而是放一根绳子(指针),绳子上串着很多卡片(Linked List)。
- 这就是“拉链法”:
key % capacity算出抽屉编号,如果冲突了,就串在同一个抽屉的绳子上。
-
头插法 (
buckets[idx] = new Node(..., buckets[idx])):- 这是插入链表最快的方式。不管链表有多长,新来的直接做“老大”(排在第一个),把原来的老大接在自己后面。
- 复杂度永远是 。
-
扩容 (
resize) 的必要性:- 如果不扩容,随着数据越来越多,绳子(链表)会越来越长,查找就变成了遍历长链表,速度变慢。
- 扩容就是“买个更大的柜子”,把旧卡片重新算位置放进去,保证每根绳子都很短。
-
删除 (
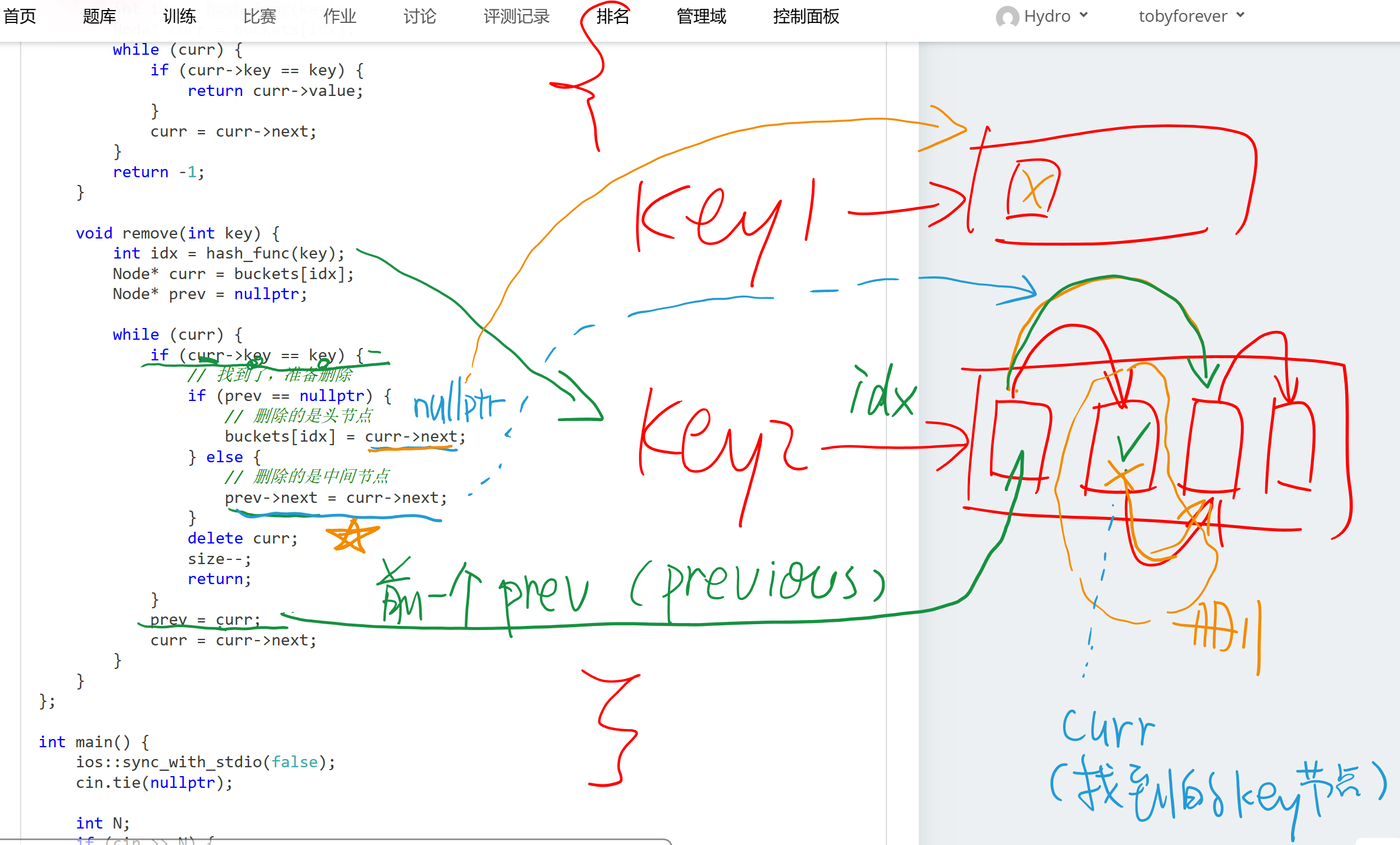
remove) 的指针技巧:- 删除链表节点时,需要把“前一个人的手”牵到“后一个人”身上。
- 特判:如果删除的是第一个人(头节点),没有“前一个人”,直接把“柜子标签”改成第二个人即可。
哈希表内部结构 / 删除技巧
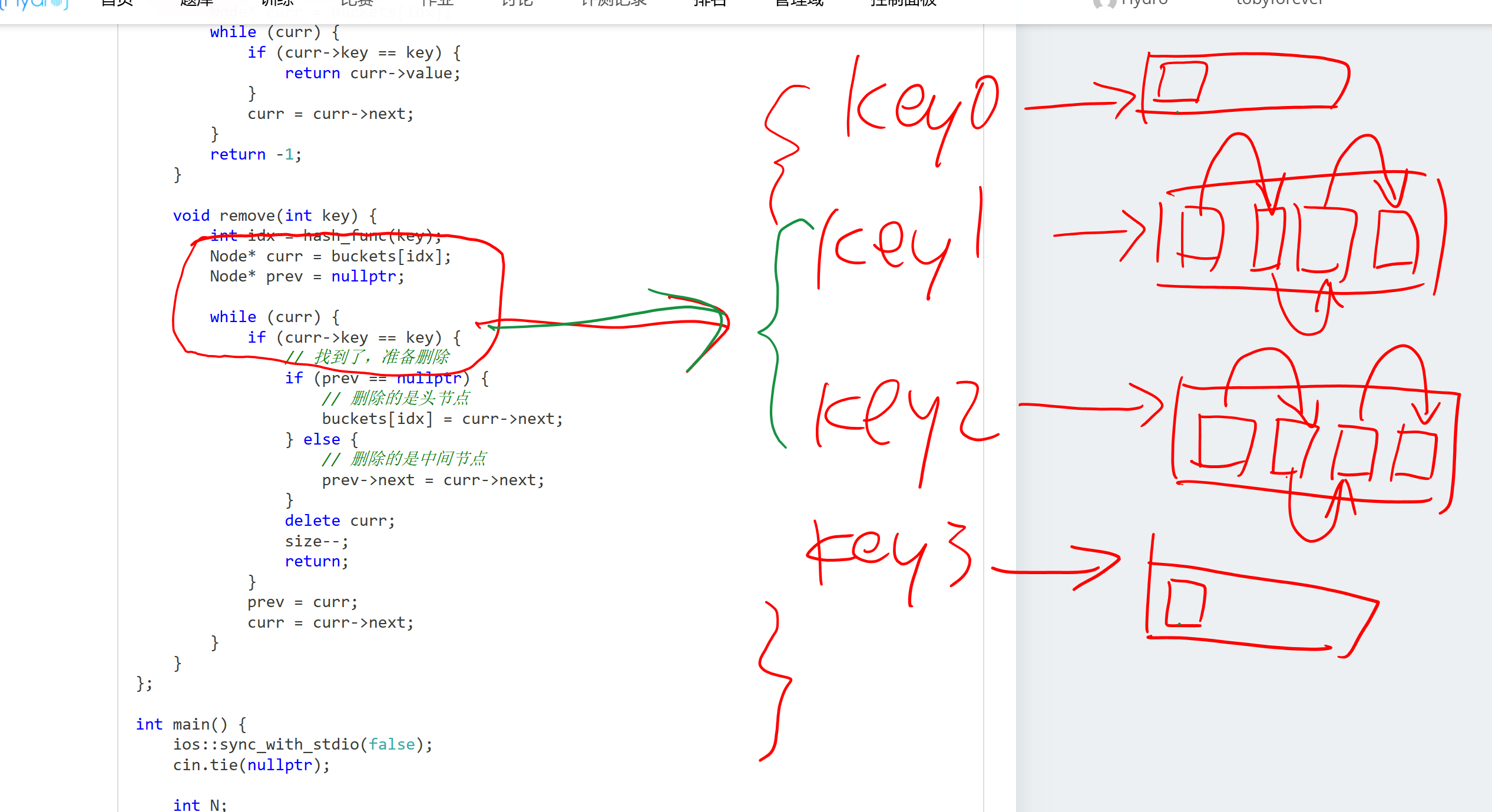
链表删除中间元素
-
0
这是一个完整的 C++ 数据生成器。它不仅生成
.in输入文件,还会利用 STL 的unordered_map作为“标准答案”生成对应的.out输出文件。该生成器包含 10 个测试点,设计逻辑覆盖了:小数据、大数据压测、大量哈希冲突(针对模数攻击)、频繁增删改、扩容触发测试以及边界值测试。
使用说明
- 将下方代码保存为
gen.cpp。 - 编译:
g++ gen.cpp -o gen -O2 -std=c++14 - 运行:
./gen - 运行结束后,当前目录下会生成
1.in/1.out到10.in/10.out。
数据生成器代码 (C++14)
#include <iostream> #include <fstream> #include <vector> #include <string> #include <random> #include <unordered_map> #include <algorithm> #include <chrono> using namespace std; // 配置参数 const int TOTAL_POINTS = 10; const int MAX_KEY = 1000000000; // 随机数生成器初始化 mt19937 rng(chrono::steady_clock::now().time_since_epoch().count()); // 生成指定范围内的随机整数 [l, r] int rand_int(int l, int r) { uniform_int_distribution<int> dist(l, r); return dist(rng); } // --------------------------------------------------------- // 标准答案模拟器 (用于生成 .out 文件) // 使用 std::unordered_map 保证逻辑正确性 // --------------------------------------------------------- class StdSolver { unordered_map<int, int> mp; public: void put(int k, int v) { mp[k] = v; } int get(int k) { if (mp.find(k) != mp.end()) { return mp[k]; } return -1; } void remove(int k) { mp.erase(k); } void clear() { mp.clear(); } }; // --------------------------------------------------------- // 测试点生成逻辑 // --------------------------------------------------------- void generate_point(int point_id) { string in_file = to_string(point_id) + ".in"; string out_file = to_string(point_id) + ".out"; ofstream fin(in_file); ofstream fout(out_file); StdSolver solver; vector<int> known_keys; // 用于记录已知存在的key,方便生成有效的get/remove操作 int N; // 操作数量 // 针对不同测试点的策略配置 if (point_id <= 2) { // Points 1-2: 小规模数据,基础功能测试 N = 100; int key_range = 50; fin << N << endl; for (int i = 0; i < N; ++i) { int op = rand_int(0, 2); // 0: put, 1: get, 2: remove if (op == 0) { int k = rand_int(1, key_range); int v = rand_int(1, 1000); fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } else if (op == 1) { // 50% 概率查存在的,50% 概率查随机的 int k = (known_keys.empty() || rand_int(0, 1)) ? rand_int(1, key_range) : known_keys[rand_int(0, known_keys.size()-1)]; fin << "get " << k << endl; fout << solver.get(k) << endl; } else { int k = (known_keys.empty() || rand_int(0, 1)) ? rand_int(1, key_range) : known_keys[rand_int(0, known_keys.size()-1)]; fin << "remove " << k << endl; solver.remove(k); } } } else if (point_id <= 4) { // Points 3-4: 纯插入与查询,主要测试扩容后的查找 N = 100000; fin << N << endl; // 前 70% 是插入,后 30% 是查询 for (int i = 0; i < N; ++i) { if (i < N * 0.7) { int k = rand_int(1, MAX_KEY); int v = rand_int(1, MAX_KEY); fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } else { int k = (known_keys.empty() || rand_int(0, 3)) ? rand_int(1, MAX_KEY) : known_keys[rand_int(0, known_keys.size()-1)]; fin << "get " << k << endl; fout << solver.get(k) << endl; } } } else if (point_id <= 6) { // Points 5-6: 频繁更新与删除,测试内存复用和链表删除逻辑 N = 100000; fin << N << endl; int key_range = 5000; // 较小的 Key 范围意味着高重复率(Update) for (int i = 0; i < N; ++i) { int op = rand_int(0, 9); // 40% put, 30% get, 30% remove if (op < 4) { int k = rand_int(1, key_range); int v = rand_int(1, MAX_KEY); fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } else if (op < 7) { int k = rand_int(1, key_range); fin << "get " << k << endl; fout << solver.get(k) << endl; } else { int k = rand_int(1, key_range); fin << "remove " << k << endl; solver.remove(k); } } } else if (point_id == 7) { // Point 7: 扩容触发测试 (Rehash Stress Test) // 持续插入不同的 Key,强制哈希表从 16 -> 32 -> ... -> 大容量 N = 100000; fin << N << endl; for(int i = 0; i < N; ++i) { // 每隔 100 次做一次查询,其余全插入 if (i % 100 == 0 && !known_keys.empty()) { int k = known_keys[rand_int(0, known_keys.size()-1)]; fin << "get " << k << endl; fout << solver.get(k) << endl; } else { int k = i; // 连续的 key int v = i * 10; fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } } } else if (point_id == 8) { // Point 8: 哈希冲突攻击 (Collision Test) // 构造容易冲突的数据。题目初始容量 16,扩容通常是 2 的幂次。 // 生成大量 2^k 倍数的 key,使它们在 key % capacity 时容易撞车。 N = 100000; fin << N << endl; int step = 256; // 2^8, 对低位取模容易冲突 for(int i = 0; i < N; ++i) { int op = rand_int(0, 2); if (op == 0) { int k = (i + 1) * step; // 256, 512, 768... int v = i; fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } else if (op == 1) { // 查询操作 int k = (known_keys.empty()) ? step : known_keys[rand_int(0, known_keys.size()-1)]; fin << "get " << k << endl; fout << solver.get(k) << endl; } else { // 删除操作 int k = (known_keys.empty()) ? step : known_keys[rand_int(0, known_keys.size()-1)]; fin << "remove " << k << endl; solver.remove(k); } } } else if (point_id == 9) { // Point 9: 边界情况 (Edge Cases) // Key = 0, Key = MAX_INT, 重复删除不存在的 Key N = 50000; fin << N << endl; vector<int> special_keys = {0, 1, 2, MAX_KEY, MAX_KEY - 1}; for(int i = 0; i < N; ++i) { int op = rand_int(0, 2); int k = special_keys[rand_int(0, special_keys.size() - 1)]; if (op == 0) { int v = rand_int(0, 100); fin << "put " << k << " " << v << endl; solver.put(k, v); } else if (op == 1) { fin << "get " << k << endl; fout << solver.get(k) << endl; } else { fin << "remove " << k << endl; solver.remove(k); } } } else { // Point 10: 综合随机大数据 (Mixed Large) N = 100000; fin << N << endl; for(int i = 0; i < N; ++i) { int op = rand_int(0, 2); int k = (op == 0 || known_keys.empty() || rand_int(0, 3) == 0) ? rand_int(0, MAX_KEY) : known_keys[rand_int(0, known_keys.size()-1)]; if (op == 0) { int v = rand_int(0, MAX_KEY); fin << "put " << k << " " << v << endl; solver.put(k, v); known_keys.push_back(k); } else if (op == 1) { fin << "get " << k << endl; fout << solver.get(k) << endl; } else { fin << "remove " << k << endl; solver.remove(k); } } } fin.close(); fout.close(); cout << "Test point " << point_id << " generated." << endl; } int main() { // 提升 IO 效率,虽然对生成器不是必须的 ios_base::sync_with_stdio(false); cin.tie(NULL); cout << "Generating " << TOTAL_POINTS << " test cases..." << endl; for (int i = 1; i <= TOTAL_POINTS; ++i) { generate_point(i); } cout << "Done! Files 1.in/out through 10.in/out created." << endl; return 0; }数据点设计策略详解
测试点 ID 数据规模 N 说明 考察点 1-2 100 小范围 Key,少量操作 算法正确性,基本逻辑 3-4 100,000 大范围 Key,主要是 put和get大数据量下的基本哈希性能 5-6 Key 范围小 (5000),高频重复 哈希冲突处理 (拉链法)、值更新、链表节点查找 7 连续 Key,只增不减 扩容 (Rehash) 逻辑是否正确,是否因扩容导致超时 8 Key 为 256 的倍数 哈希攻击,测试哈希函数是否均匀,或链表过长时的性能 9 50,000 包含 0, INT_MAX, 不存在的 Key 边界条件,删除不存在的元素,查询空元素 10 100,000 纯随机大数据 综合稳定性测试 注意事项
- 文件大小:输入文件中全是整数和简单的指令字符串。对于 ,每行平均约 15 字节,总大小约 1.5MB,符合 2MB 的限制。
- 效率:使用了
std::unordered_map作为参考答案,其本身效率极高,生成 10 组数据在现代 CPU 上通常在 1 秒内完成。 - 安全性:代码中避免了除以 0,且使用了
vector记录已生成的 key 来保证get和remove操作有较高的命中率(避免全部输出 -1 导致测试无效)。
- 将下方代码保存为
-
0
这里是为您准备的《Unordered Map 模拟》题解资料。我将按照从暴力模拟到标准实现,再到竞赛最优优化的顺序,给出三个版本的代码。
版本一:暴力扫描法 (Brute Force)
适用场景:验证逻辑正确性、对拍(Validator)、极小数据范围 ()。 思路:使用一个
std::vector存储所有键值对。每次操作都遍历整个数组。 瓶颈:查询和删除都需要遍历,单次操作 ,总复杂度 。在 时会严重超时(TLE)。/* * 版本 1: 暴力扫描 (Brute Force) * 时间复杂度: O(N^2) - 必定 TLE * 空间复杂度: O(N) */ #include <iostream> #include <vector> #include <string> using namespace std; struct Node { int key; int value; }; vector<Node> data_store; // 查找 Key 在 vector 中的索引,找不到返回 -1 int find_index(int key) { for (size_t i = 0; i < data_store.size(); ++i) { if (data_store[i].key == key) { return i; } } return -1; } int main() { // 基础 IO 优化 ios::sync_with_stdio(false); cin.tie(nullptr); int N; if (!(cin >> N)) return 0; string op; int x, y; while (N--) { cin >> op; if (op == "put") { cin >> x >> y; int idx = find_index(x); if (idx != -1) { data_store[idx].value = y; // 存在则更新 } else { data_store.push_back({x, y}); // 不存在则追加 } } else if (op == "get") { cin >> x; int idx = find_index(x); if (idx != -1) { cout << data_store[idx].value << "\n"; } else { cout << "-1\n"; } } else if (op == "remove") { cin >> x; int idx = find_index(x); if (idx != -1) { // 小技巧:将待删除元素与最后一个元素交换,然后 pop_back // 这样避免了 vector 移动元素的 O(N) 开销,虽然查找本身已经是 O(N) swap(data_store[idx], data_store.back()); data_store.pop_back(); } } } return 0; }
版本二:标准拉链法哈希表 (Standard Chaining Hash Map)
适用场景:通用的哈希表实现,面试或标准的 CS 课程作业。 思路:
- 动态数组
buckets:存放链表头指针。 - 链表
Node:解决哈希冲突。 - Rehash:当元素数量超过容量的 0.75 时,容量翻倍,所有旧节点重新计算哈希值挂入新表。
特点:使用 C++ 指针和
new/delete,逻辑非常清晰,符合面向对象设计。
/* * 版本 2: 动态扩容哈希表 (指针版) * 时间复杂度: 平均 O(1),最坏 O(N) * 空间复杂度: O(N) * 知识点: 链表操作、动态内存管理、Rehash */ #include <iostream> #include <string> #include <vector> using namespace std; // 链表节点结构 struct Node { int key; int value; Node* next; Node(int k, int v, Node* n) : key(k), value(v), next(n) {} }; class MyHashMap { private: Node** buckets; // 指针数组 (Bucket Array) int capacity; // 当前容量 (桶的数量) int size; // 当前元素个数 const double LOAD_FACTOR = 0.75; // 哈希函数 int hash_func(int key) { // 应对负数 key 的情况 (本题虽说是正数,但习惯要好) return (key % capacity + capacity) % capacity; } // 扩容函数 (Rehash) void resize() { int old_capacity = capacity; int new_capacity = capacity * 2; Node** old_buckets = buckets; // 1. 初始化新桶数组 buckets = new Node*[new_capacity]; for (int i = 0; i < new_capacity; ++i) buckets[i] = nullptr; capacity = new_capacity; // 更新容量,供 hash_func 使用 // 2. 搬运节点 (Rehash) for (int i = 0; i < old_capacity; ++i) { Node* curr = old_buckets[i]; while (curr != nullptr) { Node* next_node = curr->next; // 先保存下一个,因为 curr->next 即将修改 // 计算在新表中的位置 int idx = hash_func(curr->key); // 头插法插入新表 curr->next = buckets[idx]; buckets[idx] = curr; curr = next_node; } } // 3. 释放旧桶数组 (注意:节点本身没被删除,只是被移动了) delete[] old_buckets; } public: MyHashMap() { capacity = 16; // 初始容量 size = 0; buckets = new Node*[capacity]; for (int i = 0; i < capacity; ++i) buckets[i] = nullptr; } ~MyHashMap() { // 析构函数:释放所有内存 for (int i = 0; i < capacity; ++i) { Node* curr = buckets[i]; while (curr) { Node* tmp = curr; curr = curr->next; delete tmp; } } delete[] buckets; } void put(int key, int value) { int idx = hash_func(key); Node* curr = buckets[idx]; // 1. 检查是否存在,存在则更新 while (curr) { if (curr->key == key) { curr->value = value; return; } curr = curr->next; } // 2. 不存在,创建新节点 (头插法) buckets[idx] = new Node(key, value, buckets[idx]); size++; // 3. 检查负载因子,是否需要扩容 if (size >= capacity * LOAD_FACTOR) { resize(); } } int get(int key) { int idx = hash_func(key); Node* curr = buckets[idx]; while (curr) { if (curr->key == key) { return curr->value; } curr = curr->next; } return -1; } void remove(int key) { int idx = hash_func(key); Node* curr = buckets[idx]; Node* prev = nullptr; while (curr) { if (curr->key == key) { // 找到了,准备删除 if (prev == nullptr) { // 删除的是头节点 buckets[idx] = curr->next; } else { // 删除的是中间节点 prev->next = curr->next; } delete curr; size--; return; } prev = curr; curr = curr->next; } } }; int main() { ios::sync_with_stdio(false); cin.tie(nullptr); int N; if (cin >> N) { MyHashMap map; string op; int x, y; while (N--) { cin >> op; if (op == "put") { cin >> x >> y; map.put(x, y); } else if (op == "get") { cin >> x; cout << map.get(x) << "\n"; } else if (op == "remove") { cin >> x; map.remove(x); } } } return 0; }
版本三:竞赛最优版 (Memory Pool Optimization)
适用场景:NOI/ICPC 金牌选手标准。对时间常数要求极高,防止内存碎片化。 优化点:
- 内存池 (Memory Pool):不使用
new Node,而是预先开一个大数组nodes[]。节点的next指针改为int next(数组下标)。- 优势:避免了
new的系统调用开销,缓存命中率极高。
- 优势:避免了
- 位运算取模:如果保证
capacity永远是 2 的幂次,key % capacity可以优化为key & (capacity - 1)。 - Fast IO:在
main中使用。
/* * 版本 3: 静态内存池优化版 (OI Style) * 时间复杂度: 均摊 O(1),常数极小 * 空间复杂度: O(N) * 优化: 避免动态 new/delete,使用数组模拟链表 */ #include <iostream> #include <vector> #include <cstring> using namespace std; // 预分配的最大节点数 (对应 N 的最大范围) const int MAX_NODES = 100005; struct Node { int key; int val; int next; // 存储的是 nodes 数组的下标,0 表示空指针 } nodes[MAX_NODES]; int idx_alloc = 0; // 内存池分配指针 // 简单的内存分配器 int new_node(int k, int v, int nxt) { ++idx_alloc; nodes[idx_alloc].key = k; nodes[idx_alloc].val = v; nodes[idx_alloc].next = nxt; return idx_alloc; } class FastHashMap { private: vector<int> buckets; // 桶数组,存的是 node 的下标 int capacity; int size; // 负载因子阈值:size * 4 > capacity * 3 <=> size > capacity * 0.75 // 使用整数乘法避免浮点误差 bool check_load_factor() { return (long long)size * 4 > (long long)capacity * 3; } public: FastHashMap() { capacity = 16; size = 0; buckets.assign(capacity, 0); // 0 表示 nullptr idx_alloc = 0; // 重置内存池 } void put(int key, int val) { // 位运算优化取模 (前提:capacity 是 2 的幂) // int idx = key % capacity; int idx = key & (capacity - 1); // 遍历链表查找是否存在 for (int cur = buckets[idx]; cur != 0; cur = nodes[cur].next) { if (nodes[cur].key == key) { nodes[cur].val = val; // 更新 return; } } // 不存在,插入新节点 (头插法) // new_node 从静态数组分配,速度极快 buckets[idx] = new_node(key, val, buckets[idx]); size++; // 检查扩容 if (check_load_factor()) { resize(); } } int get(int key) { int idx = key & (capacity - 1); for (int cur = buckets[idx]; cur != 0; cur = nodes[cur].next) { if (nodes[cur].key == key) { return nodes[cur].val; } } return -1; } void remove(int key) { int idx = key & (capacity - 1); int cur = buckets[idx]; int prev = 0; while (cur != 0) { if (nodes[cur].key == key) { if (prev == 0) { // 删除头节点 buckets[idx] = nodes[cur].next; } else { // 删除中间节点 nodes[prev].next = nodes[cur].next; } // 注意:静态内存池通常不回收内存(Lazy Delete),因为总操作数有限 // 仅仅断开链接即可。size 减小。 size--; return; } prev = cur; cur = nodes[cur].next; } } void resize() { int old_capacity = capacity; int new_capacity = capacity << 1; // * 2 // 创建新的桶数组 vector<int> new_buckets(new_capacity, 0); // 遍历旧桶 for (int i = 0; i < old_capacity; ++i) { int cur = buckets[i]; while (cur != 0) { int next_node = nodes[cur].next; // 暂存后续 // 重新计算 Hash (Rehash) int new_idx = nodes[cur].key & (new_capacity - 1); // 头插法搬移到新表 nodes[cur].next = new_buckets[new_idx]; new_buckets[new_idx] = cur; cur = next_node; } } // 接管新表 buckets = move(new_buckets); capacity = new_capacity; } }; int main() { ios::sync_with_stdio(false); cin.tie(nullptr); int N; if (cin >> N) { FastHashMap map; string op; int x, y; while (N--) { cin >> op; if (op[0] == 'p') { // check 'p' of "put" cin >> x >> y; map.put(x, y); } else if (op[0] == 'g') { // check 'g' of "get" cin >> x; cout << map.get(x) << "\n"; } else { // "remove" cin >> x; map.remove(x); } } } return 0; }
👨🏫 核心知识点与复杂度分析
1. 为什么需要 Rehash (扩容)?
- 思考:如果不扩容,随着插入元素越来越多,
size远大于capacity。根据鸽巢原理,每个桶(Bucket)里的链表会变得非常长。 - 后果:查找时间从 退化为 ( 为桶数),甚至 。
- 策略:通过扩容(通常翻倍),
capacity变大,链表被拆散重新分布,平均长度再次回到常数级别。
2. 时间复杂度分析
- 普通操作 (put/get):
- 计算 Hash:
- 定位桶:
- 遍历链表: 平均链表长度 = (0.75)。这是一个常数。
- 结论: 平均 。
- 扩容操作:
- 需要遍历所有旧节点( 个),重新计算 Hash。单次复杂度 。
- 均摊分析 (Amortized Analysis):
- 第 1 次扩容:搬运 16 个。
- 第 2 次扩容:搬运 32 个。
- ...
- 第 k 次扩容:搬运 个。
- 总搬运次数约为 。
- 将这 的代价分摊到 次插入操作中,每次操作只分摊了 。
- 结论: 均摊 。
3. 空间复杂度分析
- 需要存储 个节点 + 个桶头指针。
- 因为 ,所以总体为 。
4. 金牌选手的优化思路 (在版本 3 中体现)
- 静态数组 vs 动态指针:
new是一种非常慢的操作(涉及堆内存分配算法)。在竞赛中,预先分配一个大数组Node pool[MAX_N]并使用整数下标代替指针,可以显著提升速度(Cache Friendly)。 - 位运算取模: 计算机做除法(
%)比位运算(&)慢得多。如果桶大小保证是 ,x % 2^k等价于x & (2^k - 1)。 - 字符串读取优化: 读取操作指令时,判断
op[0]('p', 'g', 'r') 比比较整个字符串op == "put"更快。
- 动态数组
- 1
信息
- ID
- 19472
- 时间
- 1000ms
- 内存
- 128MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 5
- 已通过
- 2
- 上传者
-