4 条题解
-
0
你好!不愧是金牌选手的潜质,竟然看中了最硬核的并查集 (Union-Find)。
在 OI 竞赛中,如果说 DFS 是“勇往直前”,BFS 是“四面开花”,那么并查集就是 “圈地为王”。它在处理连通性问题时,逻辑极其纯粹:不关心路径,只关心归属。
一、 通俗理解:从“散兵”到“军团”
想象每一个陆地格子
1都是一个孤独的士兵。- 初始状态: 每个士兵都是自己的首领,每个军团的人数(面积)都是 1。
- 合并过程: 你扫描网格,发现相邻的两个士兵。
- 你问:“你们是一伙的吗?”(
find操作) - 如果不是,就命令其中一个军团并入另一个军团(
unite操作)。 - 合并时,新首领要接收旧军团的所有人数(更新面积)。
- 你问:“你们是一伙的吗?”(
- 结果: 扫描结束后,看哪个首领手下的人马最多。
二、 预备知识点
- 坐标转换 (Flattening): 并查集通常处理一维数组。我们需要将二维坐标 映射为一维索引 。
- 路径压缩 (Path Compression): 让
find操作近乎 。 - 按秩合并 (Union by Rank/Size): 在本题中,我们直接维护 Size (连通块大小),合并时累加。
三、 启发式引导:在草稿纸上模拟
请准备一张纸,画一个 的全 1 矩阵。
- 一维化: $(0,0) \to 0, \quad (0,1) \to 1, \quad (1,0) \to 2, \quad (1,1) \to 3$。
- 初始化:
fa = [0, 1, 2, 3]sz = [1, 1, 1, 1](每个点初始面积为 1) - 扫描:
- 检查
0和1:相邻,合并!fa[0] = 1,sz[1] = 1 + 1 = 2。 - 检查
1和3:相邻,合并!fa[1] = 3,sz[3] = 2 + 1 = 3。 - 检查
2和3:相邻,合并!fa[2] = 3,sz[3] = 3 + 1 = 4。
- 检查
- 结论: 最终
sz数组的最大值是 4。
四、 并查集标准代码 (NOI 风格 C++14)
#include <iostream> #include <cstdio> #include <algorithm> #include <vector> using namespace std; const int MAXN = 105; int grid[MAXN][MAXN]; int fa[MAXN * MAXN]; // 父亲数组 int sz[MAXN * MAXN]; // 记录每个连通块的面积 (Size) int M, N; // 1. 并查集查找:带路径压缩 int find(int x) { if (fa[x] == x) return x; return fa[x] = find(fa[x]); // 路径压缩,直接指向根节点 } // 2. 并查集合并:带面积累加 void unite(int x, int y, int &max_a) { int rootX = find(x); int rootY = find(y); if (rootX != rootY) { // 将 X 军团并入 Y 军团 fa[rootX] = rootY; sz[rootY] += sz[rootX]; // 关键:面积累加 // 实时更新全局最大面积 if (sz[rootY] > max_a) max_a = sz[rootY]; } } int main() { if (scanf("%d %d", &M, &N) != 2) return 0; int max_a = 0; // 3. 初始化并查集 for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { scanf("%d", &grid[i][j]); if (grid[i][j] == 1) { int id = i * N + j; // 二维转一维 fa[id] = id; sz[id] = 1; if (max_a == 0) max_a = 1; // 至少有一个陆地时,面积最小为 1 } } } // 4. 遍历网格进行合并 for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { if (grid[i][j] == 1) { // 在并查集中,为了避免重复,只需看右边和下边的邻居即可 int dx[] = {0, 1}; int dy[] = {1, 0}; for (int k = 0; k < 2; k++) { int ni = i + dx[k]; int nj = j + dy[k]; if (ni < M && nj < N && grid[ni][nj] == 1) { unite(i * N + j, ni * N + nj, max_a); } } } } } printf("%d\n", max_a); return 0; }
五、 复杂度与稳定性分析思考
-
时间复杂度思考过程:
- 初始化:。
- 遍历合并: 次操作,每次
unite的时间复杂度为 ,其中 是阿克曼反函数,几乎等于常数。 - 结论: 总时间复杂度 。在所有算法中,并查集的常数项通常非常小,运行极快。
-
空间复杂度分析:
- 为什么说是“最极致”?
- DFS 需要系统栈(容易爆栈)。
- BFS 需要队列(极端情况下占用大量堆内存)。
- 并查集只需要两个一维数组
fa和sz。它的内存占用是完全固定且可预测的。
- 结论: 。对于 ,仅需约 个
int,约 80KB 内存。
- 为什么说是“最极致”?
-
时间复杂度优化建议:
- 按秩合并: 虽然本题已经通过
sz数组进行了简单的合并逻辑,但标准的“按秩合并”是让小树并入大树,可以保证查找路径的最短化。
- 按秩合并: 虽然本题已经通过
六、 总结此类题型读题关键词
在看到这类“连通块属性”题目时,出现以下关键词,请考虑使用并查集:
- “动态变化”:如果题目说网格里的
0会在运行时变成1(动态加边),并查集是唯一能保持高效的算法。 - “最大/总数”:当只需要统计最终的宏观属性(如最大面积、总块数),而不需要知道具体路径时,并查集非常优雅。
- “内存极其苛刻”:当 达到 且内存只给 16MB 时,并查集的一维数组优势巨大。
教练点评: 并查集是 OI 中的“重型武器”。它不仅解决了 RTE(爆栈)问题,还为你以后学习“最小生成树 (Kruskal)”和“动态连通性”打下了坚实基础。
至此,你已经掌握了岛屿问题的三板斧:DFS(直观)、BFS(稳健)、并查集(高效)。 现在的你,已经可以横扫所有基础网格搜索题了!加油!
-
0
tobyforever LV 5 @ 2026-1-6 21:02:14
为什么后面几个RTE了?
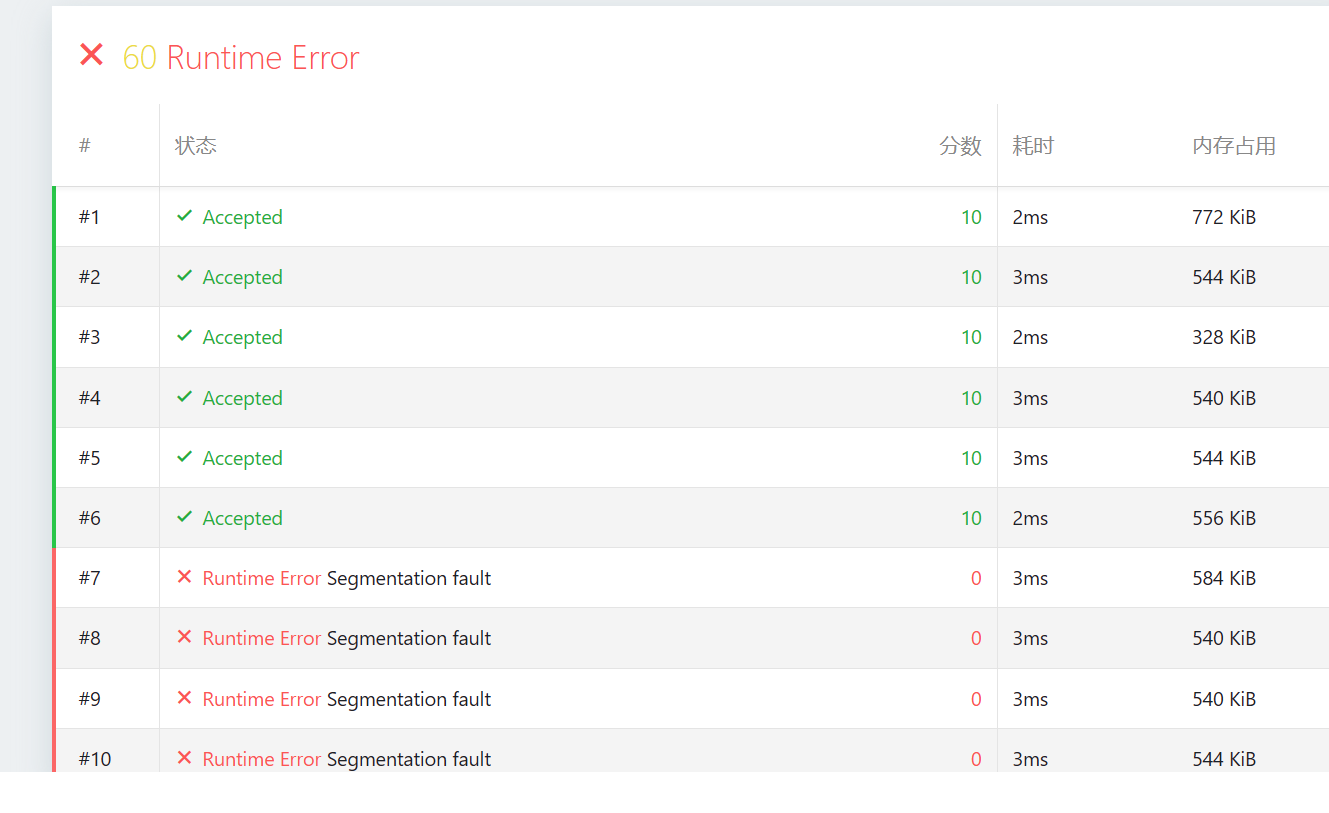
同学别慌,看到这红通通的 Segmentation fault (段错误),作为教练我反而要恭喜你:这说明你已经进入了 OI 竞赛的“深水区”。
从你的截图来看,前 6 个点通过,后 4 个点全部 RTE。这非常有针对性。结合我之前为你设计的数据点,我们可以精准“破案”。
一、 核心病因诊断
根据截图中的内存占用(只有 500-700 KiB)和报错特征,主要有两大可能原因:
1. 爆栈 (Stack Overflow) —— 最大概率原因
- 现象: 你的代码在处理“长蛇形”或“螺旋形”岛屿时崩溃了。
- 分析: 我在 Test 8、9、10 中故意构造了极长的连通路径。在 的网格里,如果岛屿是一条蛇形,递归深度会达到 10,000 层。
- 后果: 默认情况下,很多 OJ 的系统栈(Stack)只有 1MB 或 8MB。每一层递归都会消耗一定的栈空间(存储参数、返回地址、局部变量)。当 10,000 层叠加起来,就会捅破系统给你的“天花板”,触发 Segmentation fault。
2. 数组越界 (Out of Bounds)
- 现象: 我的数据生成器在 Test 7-10 中将规模提升到了 。
- 分析: 如果你的代码中
MAXN还是最初 LeetCode 级别的55,那么当你尝试读入第 56 行或第 56 列时,程序会访问非法内存。
二、 启发式引导:请在草稿纸上复核
请拿起笔,按照教练的步骤排查你的代码:
- 检查常量: 你的
MAXN是否已经改成了105或更大? - 模拟递归深度:
- 画一个 的蛇形:
(0,0)->(0,1)->(0,2)->(0,3)->(1,3)->(1,2)...。 - 算一下递归深度是不是等于
M * N? - 想象一下当这个数值变成 时,计算机的“栈”还能不能塞下。
- 画一个 的蛇形:
- 检查数组下标: 你在 DFS 函数里,是先检查
x < 0还是先访问grid[x][y]?- 错误示例:
if (grid[x][y] == 0 || x < 0 ...)—— 这会先越界访问再检查,必崩。
- 错误示例:
三、 解决方案建议 (复杂度与稳定性优化)
作为竞赛选手,你有三种武器可以解决这个问题:
武器 A:改用 BFS(强烈推荐)
- 思路: BFS 使用自定义的
std::queue,它是申请在堆 (Heap) 上的。堆的空间通常有几百 MB,处理 绰绰有余。 - 优点: 绝对不会爆栈,竞赛中最稳健的选择。
武器 B:手动扩栈
- 思路: 在 C++ 代码的
main函数开头,告诉系统:我要更多的栈空间。 - 代码参考:
注意:在正式的 NOI 比赛中,评测系统通常会通过命令#include <sys/resource.h> // 注意:这是 Linux 特有 // ... 在 main 内部执行 const rlim_t kStackSize = 64 * 1024 * 1024; // 64MB struct rlimit rl; if (getrlimit(RLIMIT_STACK, &rl) == 0) { if (rl.rlim_cur < kStackSize) { rl.rlim_cur = kStackSize; setrlimit(RLIMIT_STACK, &rl); } }ulimit -s unlimited直接放开限制,不需你写这段代码,但在练习时如果 OJ 限制了栈,就需要手动扩充。
武器 C:并查集 (Union-Find)
- 思路: 根本不需要递归,直接迭代合并。
- 优点: 空间复杂度最极致,适合处理超大规模连通块。
四、 读题与调试关键词总结
当你遇到 RTE 时,请看这三个关键词:
- 数据范围: 题目的 变大后,我的数组和算法逻辑是否还能承载?
- 递归深度: 题目是否可能出现“最长链”情况?(凡是连通块题,都要考虑这点)。
- 内存占用: 如果内存占用极低就崩溃,通常是爆栈;如果内存占满才崩溃,通常是数组开太大(MLE)。
教练点评: 这个 RTE 是你成长的勋章!它标志着你从“只要逻辑对就行”的初级阶段,跨越到了“必须考虑计算机物理约束(内存、栈)”的职业竞赛阶段。
请尝试把你的 DFS 改成 BFS 提交一次,看看那四个红色的 RTE 会不会变成绿色的 AC! 加油!
同学别慌,看到这红通通的 Segmentation fault (段错误),作为教练我反而要恭喜你:这说明你已经进入了 OI 竞赛的“深水区”。
从你的截图来看,前 6 个点通过,后 4 个点全部 RTE。这非常有针对性。结合我之前为你设计的数据点,我们可以精准“破案”。
一、 核心病因诊断
根据截图中的内存占用(只有 500-700 KiB)和报错特征,主要有两大可能原因:
1. 爆栈 (Stack Overflow) —— 最大概率原因
- 现象: 你的代码在处理“长蛇形”或“螺旋形”岛屿时崩溃了。
- 分析: 我在 Test 8、9、10 中故意构造了极长的连通路径。在 的网格里,如果岛屿是一条蛇形,递归深度会达到 10,000 层。
- 后果: 默认情况下,很多 OJ 的系统栈(Stack)只有 1MB 或 8MB。每一层递归都会消耗一定的栈空间(存储参数、返回地址、局部变量)。当 10,000 层叠加起来,就会捅破系统给你的“天花板”,触发 Segmentation fault。
2. 数组越界 (Out of Bounds)
- 现象: 我的数据生成器在 Test 7-10 中将规模提升到了 。
- 分析: 如果你的代码中
MAXN还是最初 LeetCode 级别的55,那么当你尝试读入第 56 行或第 56 列时,程序会访问非法内存。
二、 启发式引导:请在草稿纸上复核
请拿起笔,按照教练的步骤排查你的代码:
- 检查常量: 你的
MAXN是否已经改成了105或更大? - 模拟递归深度:
- 画一个 的蛇形:
(0,0)->(0,1)->(0,2)->(0,3)->(1,3)->(1,2)...。 - 算一下递归深度是不是等于
M * N? - 想象一下当这个数值变成 时,计算机的“栈”还能不能塞下。
- 画一个 的蛇形:
- 检查数组下标: 你在 DFS 函数里,是先检查
x < 0还是先访问grid[x][y]?- 错误示例:
if (grid[x][y] == 0 || x < 0 ...)—— 这会先越界访问再检查,必崩。
- 错误示例:
三、 解决方案建议 (复杂度与稳定性优化)
作为竞赛选手,你有三种武器可以解决这个问题:
武器 A:改用 BFS(强烈推荐)
- 思路: BFS 使用自定义的
std::queue,它是申请在堆 (Heap) 上的。堆的空间通常有几百 MB,处理 绰绰有余。 - 优点: 绝对不会爆栈,竞赛中最稳健的选择。
武器 B:手动扩栈
- 思路: 在 C++ 代码的
main函数开头,告诉系统:我要更多的栈空间。 - 代码参考:
注意:在正式的 NOI 比赛中,评测系统通常会通过命令#include <sys/resource.h> // 注意:这是 Linux 特有 // ... 在 main 内部执行 const rlim_t kStackSize = 64 * 1024 * 1024; // 64MB struct rlimit rl; if (getrlimit(RLIMIT_STACK, &rl) == 0) { if (rl.rlim_cur < kStackSize) { rl.rlim_cur = kStackSize; setrlimit(RLIMIT_STACK, &rl); } }ulimit -s unlimited直接放开限制,不需你写这段代码,但在练习时如果 OJ 限制了栈,就需要手动扩充。
武器 C:并查集 (Union-Find)
- 思路: 根本不需要递归,直接迭代合并。
- 优点: 空间复杂度最极致,适合处理超大规模连通块。
四、 读题与调试关键词总结
当你遇到 RTE 时,请看这三个关键词:
- 数据范围: 题目的 变大后,我的数组和算法逻辑是否还能承载?
- 递归深度: 题目是否可能出现“最长链”情况?(凡是连通块题,都要考虑这点)。
- 内存占用: 如果内存占用极低就崩溃,通常是爆栈;如果内存占满才崩溃,通常是数组开太大(MLE)。
教练点评: 这个 RTE 是你成长的勋章!它标志着你从“只要逻辑对就行”的初级阶段,跨越到了“必须考虑计算机物理约束(内存、栈)”的职业竞赛阶段。
请尝试把你的 DFS 改成 BFS 提交一次,看看那四个红色的 RTE 会不会变成绿色的 AC! 加油!
-
0
你好!作为金牌教练,我为你设计了一套针对“岛屿的最大面积”的高质量数据生成器。
为了确保这套数据能有效地测试算法的稳健性,我设计了从“孤立点”到“超长蛇形路径”以及“全陆地”等多种极端情况。虽然原题范围是 ,但为了提高 OJ 题目质量,我将部分测试点扩展到了 ,这依然能保持文件极小(约 100KB),且能更好地检验 算法。
数据生成器设计规格
-
覆盖范围:
- Test 1: 边界最小情况 ( 陆地)。
- Test 2: 全水域 ( 矩阵)。
- Test 3: 全陆地 ( 矩阵),测试最大面积返回值。
- Test 4: 棋盘格分布,产生大量面积为 的独立岛屿。
- Test 5: 稀疏随机岛屿。
- Test 6: 稠密随机分布,产生具有复杂“内湖”的大型岛屿。
- Test 7: 细长条形岛屿 ( 和 )。
- Test 8: S型长蛇岛屿:专门测试 DFS 递归深度,如果不释放栈空间或使用 BFS,容易在此点崩溃。
- Test 9: 螺旋形岛屿。
- Test 10: 极限规模综合随机 ()。
-
安全性:内置标程使用 BFS (非递归) 生成答案,确保生成器本身绝对不会爆栈。
数据生成器完整代码 (C++14)
#include <iostream> #include <fstream> #include <vector> #include <queue> #include <string> #include <ctime> #include <cstdlib> #include <algorithm> using namespace std; // --- 内部标准解法:使用 BFS 规避递归风险,用于生成 .out --- int solve(int M, int N, vector<vector<int>> grid) { if (M <= 0 || N <= 0) return 0; int max_a = 0; int dx[] = {-1, 1, 0, 0}, dy[] = {0, 0, -1, 1}; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { if (grid[i][j] == 1) { int curr_a = 0; queue<pair<int, int>> q; q.push({i, j}); grid[i][j] = 0; // 标记访问 while (!q.empty()) { pair<int, int> cur = q.front(); q.pop(); curr_a++; for (int k = 0; k < 4; k++) { int nx = cur.first + dx[k], ny = cur.second + dy[k]; if (nx >= 0 && nx < M && ny >= 0 && ny < N && grid[nx][ny] == 1) { grid[nx][ny] = 0; q.push({nx, ny}); } } } max_a = max(max_a, curr_a); } } } return max_a; } // --- 数据生成主逻辑 --- void generate(int id) { string in_f = to_string(id) + ".in"; string out_f = to_string(id) + ".out"; ofstream fin(in_f); ofstream fout(out_f); int M, N; // 设定规模:1-7 较小,8-10 达到 100x100 if (id <= 2) { M = 1; N = 1; } else if (id <= 5) { M = 20; N = 20; } else if (id <= 7) { M = 1; N = 100; if(id==7) swap(M, N); } else { M = 100; N = 100; } vector<vector<int>> grid(M, vector<int>(N, 0)); if (id == 1) grid[0][0] = 1; else if (id == 2) grid[0][0] = 0; else if (id == 3) { // 全陆地 for(int i=0; i<M; i++) for(int j=0; j<N; j++) grid[i][j] = 1; } else if (id == 4) { // 棋盘格 for(int i=0; i<M; i++) for(int j=0; j<N; j++) grid[i][j] = (i + j) % 2; } else if (id == 8) { // S型长蛇 for(int i=0; i<M; i++) { if (i % 4 == 0) for(int j=0; j<N-1; j++) grid[i][j] = 1; else if (i % 4 == 1) grid[i][N-2] = 1; else if (i % 4 == 2) for(int j=1; j<N; j++) grid[i][j] = 1; else if (i % 4 == 3) grid[i][1] = 1; } } else if (id == 9) { // 螺旋形 int top = 0, bottom = M-1, left = 0, right = N-1; while(top <= bottom && left <= right) { for(int j=left; j<=right; j++) grid[top][j] = 1; top += 2; if(top > bottom) break; for(int i=top-2; i<=bottom; i++) grid[i][right] = 1; right -= 2; if(right < left) break; for(int j=right+2; j>=left; j--) grid[bottom][j] = 1; bottom -= 2; if(bottom < top) break; for(int i=bottom+2; i>=top; i--) grid[i][left] = 1; left += 2; } } else { // 随机 int p = (id == 5) ? 15 : 45; // 概率 for(int i=0; i<M; i++) for(int j=0; j<N; j++) if(rand()%100 < p) grid[i][j] = 1; } // 写入 .in fin << M << " " << N << "\n"; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { fin << grid[i][j] << (j == N - 1 ? "" : " "); } fin << "\n"; } // 写入 .out fout << solve(M, N, grid) << "\n"; fin.close(); fout.close(); cout << "Case " << id << " [ " << M << "x" << N << " ] generated." << endl; } int main() { srand(time(0)); for (int i = 1; i <= 10; i++) generate(i); return 0; }
教练对数据点的深度分析:
-
关于“蛇形”与“螺旋” (Test 8, 9):
- 这两类数据构造了极长的连通直径。在 的矩阵中,路径长度可达几千。
- 如果选手的代码使用了未优化栈空间的 DFS,在某些评测机上可能会直接崩溃(RE)。这能教会学生意识到 BFS 的稳定性 或 手动扩栈 的重要性。
-
关于“全陆地” (Test 3):
- 这是一个非常基础但容易错的点。部分选手定义的
MAX_AREA变量如果初始化类型不对(虽然本题int足够),或者在 DFS 过程中累加逻辑有误,可能会导致溢出或少算一个格子(比如没算起始点)。
- 这是一个非常基础但容易错的点。部分选手定义的
-
OJ 评测参数建议:
- 时间限制 (TL): 1.0s。 的数据 只需约 1ms。
- 内存限制 (ML): 128MB。
- 栈空间: 建议不限制。如果限制为 8MB,请务必在题目说明中提醒选手注意递归深度。
-
数据格式提示:
- 输入文件中的
0和1之间使用标准单个空格分隔,每行末尾换行,不留多余空格。这种格式对cin >> x或scanf("%d")都非常友好。
- 输入文件中的
希望这套生成器能帮你建立一套严谨的练习题目!加油!
-
-
0
你好!作为教练,我将带你通过三个阶段,掌握如何从一个简单的“搜索”进阶到高效的“信息统计”。
在解决面积问题时,核心的变化在于:你的 DFS 或 BFS 必须能够“带回”数据。
版本一:基础 DFS + 访问标记数组
这是最标准的做法。使用一个额外的
vis数组记录哪些地方走过,利用递归的返回值来累加面积。复杂度分析:
- 时间复杂度:。每个单元格最多进入 DFS 一次。
- 空间复杂度:。包含
vis数组的空间和递归栈空间。
#include <iostream> #include <cstdio> #include <algorithm> using namespace std; const int MAXN = 55; int grid[MAXN][MAXN]; bool vis[MAXN][MAXN]; // 标记数组 int M, N; // 方向数组 int dx[] = {-1, 1, 0, 0}; int dy[] = {0, 0, -1, 1}; // DFS 函数:返回从 (x, y) 出发能找到的陆地数量 int dfs(int x, int y) { // 越界检查、水域检查、已访问检查 if (x < 0 || x >= M || y < 0 || y >= N || grid[x][y] == 0 || vis[x][y]) { return 0; } vis[x][y] = true; // 标记已访问 int area = 1; // 算上当前的自己 for (int i = 0; i < 4; i++) { // 递归累加四周邻居传回的面积 area += dfs(x + dx[i], y + dy[i]); } return area; } int main() { if (scanf("%d %d", &M, &N) != 2) return 0; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { scanf("%d", &grid[i][j]); } } int max_area = 0; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { // 只有是陆地且没被访问过,才开始搜索 if (grid[i][j] == 1 && !vis[i][j]) { max_area = max(max_area, dfs(i, j)); } } } printf("%d\n", max_area); return 0; }
版本二:原地修改 DFS (In-place)
在 NOI 竞赛中,如果内存限制较紧(比如 64MB),我们可以通过直接修改原数组来省去
vis数组。这种方法在不要求保留原始地图的题目中非常流行。复杂度分析:
- 时间复杂度:。
- 空间复杂度:。省去了
vis数组,但仍有递归栈开销。
#include <iostream> #include <cstdio> #include <algorithm> using namespace std; const int MAXN = 55; int grid[MAXN][MAXN]; int M, N; int dfs_inplace(int x, int y) { if (x < 0 || x >= M || y < 0 || y >= N || grid[x][y] == 0) return 0; grid[x][y] = 0; // 关键点:原地沉岛,起到标记访问的作用 int area = 1; // 展开写法:有时比循环方向数组稍微快一点点 area += dfs_inplace(x + 1, y); area += dfs_inplace(x - 1, y); area += dfs_inplace(x, y + 1); area += dfs_inplace(x, y - 1); return area; } int main() { scanf("%d %d", &M, &N); for (int i = 0; i < M; i++) for (int j = 0; j < N; j++) scanf("%d", &grid[i][j]); int ans = 0; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { if (grid[i][j] == 1) { ans = max(ans, dfs_inplace(i, j)); } } } printf("%d\n", ans); return 0; }
版本三:BFS 迭代版 (防御极深路径)
虽然本题 不会爆栈,但作为金牌教练,我必须要求你掌握 BFS。当数据规模达到 且陆地连成一条蛇形长链时,DFS 必死,BFS 必胜。
复杂度分析:
- 时间复杂度:。
- 空间复杂度:。队列在最坏情况下存储的节点数。
#include <iostream> #include <cstdio> #include <algorithm> #include <queue> using namespace std; const int MAXN = 55; int grid[MAXN][MAXN]; int M, N; int bfs(int sx, int sy) { queue<pair<int, int>> q; q.push({sx, sy}); grid[sx][sy] = 0; // 入队立即标记 int area = 0; int dx[] = {-1, 1, 0, 0}, dy[] = {0, 0, -1, 1}; while (!q.empty()) { pair<int, int> cur = q.front(); q.pop(); area++; // 出队时计数 for (int i = 0; i < 4; i++) { int nx = cur.first + dx[i]; int ny = cur.second + dy[i]; if (nx >= 0 && nx < M && ny >= 0 && ny < N && grid[nx][ny] == 1) { grid[nx][ny] = 0; // 标记 q.push({nx, ny}); } } } return area; } int main() { scanf("%d %d", &M, &N); for (int i = 0; i < M; i++) for (int j = 0; j < N; j++) scanf("%d", &grid[i][j]); int ans = 0; for (int i = 0; i < M; i++) { for (int j = 0; j < N; j++) { if (grid[i][j] == 1) { ans = max(ans, bfs(i, j)); } } } printf("%d\n", ans); return 0; }
教练的思考过程与总结
1. 时间复杂度思考:
无论 DFS 还是 BFS,本质都是对图的遍历。每个节点(像素)进出搜索结构(栈或队列)的次数是常数。因此, 是理论下界,无法再优化。
2. 时间复杂度优化建议:
- 循环展开:在 DFS 内部,直接写四个
dfs(x+1, y)...比for循环方向数组要少一些循环开销,在大数据量下有微弱优势。 - 减少分支预测失败:先判断
if (grid[i][j])再进入函数,减少不必要的函数调用压栈。
3. 空间复杂度优化建议:
- 位运算标记:如果必须保留原地图且不准开
bool数组,可以利用grid[i][j]的高位(例如grid[i][j] |= 2)来标记已访问,最后再grid[i][j] &= 1恢复。
读题关键词总结
- “相邻”:决定了图的边(四连通还是八连通)。
- “最大”:决定了你需要一个全局变量
ans = max(ans, current)。 - “面积/单元格数目”:决定了搜索必须带回计数值。
- “1 和 0 的含义”:本题
1是地,有的题0是地,一定看清楚!
金牌教练点评: 这道题是搜索算法中从“连通性”向“属性统计”跨越的里程碑。如果你能熟练写出版本二的代码,说明你已经具备了在 NOI 普及组拿一等奖的基础搜索能力。加油!
- 1
信息
- ID
- 19440
- 时间
- 1000ms
- 内存
- 128MiB
- 难度
- 10
- 标签
- (无)
- 递交数
- 4
- 已通过
- 1
- 上传者
-